背景
在数据库系统中已经发现了许多安全漏洞,其中比较严重且危害性比较大的有:缓冲区溢出和SQL注入2种。
SQL注入主要依赖于结构化查询语言,每种数据库略有出入;SQL注入漏洞的利用,最主要的威胁是提权;后台维护人员或黑客攻击,可以借此获得DBA权限。需要说明的是,这里所说的SQL注入并不是应用系统的SQL注入,而是数据库自身的注入漏洞,这种漏洞比应用系统的注入漏洞危险性更高;对于SQL注入漏洞的存在,主要是由于数据库中提供的系统或用户函数存在的参数检查不严和语句执行的缺陷。SQL注入漏洞不是本文的探讨重点,会在安华金和数据库安全实验室发表的其它文章中进行探讨。
而对于缓冲区溢出的漏洞,风险性更高,因为通过缓冲区溢出漏洞不仅可以危害数据库,还可以控制操作系统,从而以数据库服务器为跳板,控制整个内网系统。缓冲区溢出的漏洞,不仅在数据库系统中有,在操作系统上运行的相关应用软件也有,但对于数据库由于要提供大量外部访问,防火墙、IPS等传统不能对其进行禁止,这些攻击隐藏在数据库的通讯协议中,具有更大的隐蔽性,更是难以防范。
缓冲区溢出的攻击实现不仅需要注入点(注入点,是数据库的漏洞提供的),同时还要依赖于操作系统的程序调用机制来实现;现在的操作系统对此,都在逐步加强防守,但攻击者总是能够找出方法进行突破,这种突破主要依赖于shellcode的编写。缓冲区溢出本质上是因为操作系统无法区分数据和指令的区别,把数据当指令来执行,从而产生了无法预计的结果。安华金和数据库安全实验室将在本文将以windows XP为依托,借助代码对如何利用缓冲区溢出做原理性介绍,以便于我们未来对其防范原理进行更好的讨论。
缓冲区溢出
缓冲区溢简单说,是大的数据存入了小缓冲区,又不对存入数据进行边界判断,最终导致小缓冲区被撑爆。大的数据污染了小缓冲区附近的内存。污染的内存可能带来改变程序控制流、夺取操作系统、禁止访问等多种结果。下文所有的讨论都是在windows xp上进行。
缓冲区溢出主要可以分成三种:静态数据溢出、栈溢出和堆溢出。产生这三种不同的溢出根源在于win的内存结构;win的内存可以被分成两个层面:物理内存和虚拟内存。我们一般看到的其实只是windows的虚拟内存。在XP下windows会给所有进程都分配4G内存(无论物理内存真实多大);windows会把4G内存分成代码区、数据区、堆区、栈区。数据区存储的是进程的全局变量。如果利用这里的数据进行缓冲区溢出那么就被称为静态数据溢出。同样利用栈区和堆区进行缓冲区溢出,则相应被称作栈溢出和堆溢出。静态数据溢出虽然技术难度低但是灵活性和可以利用范围低,所以本文就不介绍了。堆溢出相对复杂,将在别的文章介绍。本文介绍的是windows下的栈溢出,想要知道WINDOWS下的栈溢出如何利用,首先要理解windows下的栈结构。
栈结构
为了直观的说清楚windows下的栈结构。我们构造一段代码见下图。这段代码将完成3个任务
1.演示WIN下栈的结构
2.演示缓冲区溢出改变函数控制流程
3.演示缓冲区溢出覆盖返回地址(劫持函数)
下面的程序包含一个主函数main和另外一个子函数re_choose。re_choose函数用于把从main函数中取得的输入字符串和存储的字符串liusicheng做对比。如果输入的字符串和存储的字符串一致则返回0。如果不一致则可能返回1或者-1。同时还人为制造了一个缓冲区溢出点strcpy(buffer,input)。input有1024的空间,而buffer只有44的空间。只要input超过44则就会引发缓冲区溢出。main函数取re_choose返回值如果返回1或-1走if。如果返回0则走else。将用缓冲区溢出来让返回1或者-1也走else。
#include <stdio.h>
#include <string.h>
#define ture_password”liusicheng”
int re_choose (char *input)
{
int result;
char buffer[44];
result = strcmp(input,ture_password);
strcpy(buffer,input); //缓冲注入点
return result;
}
void main()
{
int choose=0;
char input[1024];
scanf(“%s”,input);
choose=re_choose(input);
if (choose == 1 || choose == -1)
{
printf(“error\n”);
}
else
{
printf(“ture\n”);
}
}
编译出上面代码的release版,放入IDA pro中得到反编译代码。下图是MAIN函数的流程结构。清楚的看到main函数的整个控制流程和main函数的栈从建立到销毁的全过程。栈主要用在函数调用上。进程调用的开始会调用大量系统函数,其中大量函数的地址是固定不变的(只和操作系统版本有关系),这些固定的函数将成为以后用于跳转的平台。本文先不涉及这些函数。直接跳到main函数开始介绍。栈的结构是4个字节为一层。如果超过4个字节。按照4个整数倍存储。不足4个字节按照4个字节存储。栈的主要操作只有2种push和POP。push是把寄存器的内容压入到栈中,pop是把栈中的内容释放掉。ebp是当前栈帧的栈底,esp是当前栈帧的栈顶。(注意由于栈是顺序执行的所以同一时间只有一个栈顶和一个栈底。但栈底一般不是整个系统栈的栈底,而只是当前这个栈帧的栈底)。栈的结构采用先进先出,后进后出的原则。所以当创建一个栈的时候会遵循如下步骤:
1、把上一个栈帧的栈底的指针压入当前栈保存起来(push ebp)。这一步其实是2步:第一步压入返回地址,第二步压入当上一个栈帧的ebp。
2、把上一个栈帧的栈底移动到上一个栈帧的栈顶(mov ebp,esp)。从此这个栈的栈底就确定且不会发生任何改变。栈顶esp会一直发生变化。
3、接着分配局部函数(subesp,404h)。本程序中2个变量1个是4字节1个是1024字节。加一起正好是0x404个字节。需要栈顶上移0x404。注意栈的方向和内存相反。数据进入内存是从低地址向高地址写,而栈则是从高地址向低地址写。正是这种结构,给了后来数据改写之前数据的机会。栈顶的值会随着栈中数据随时进行调整。
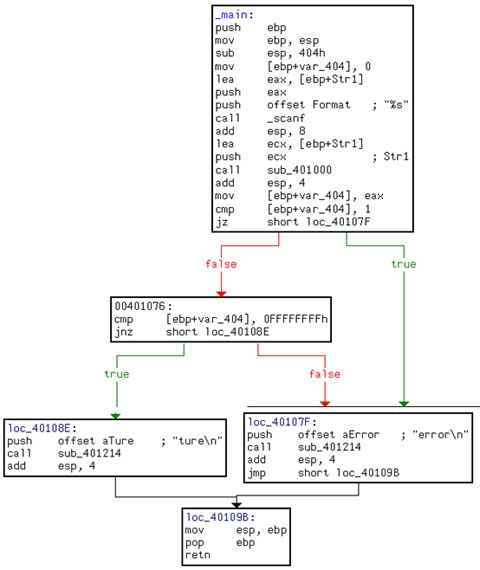
注意:上图中var_404= -404h、str1= -400h
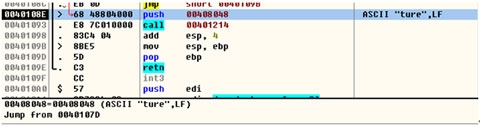
同样栈撤销的时候基本可以按照栈建立的逆操作进行。首先把栈底值覆盖栈顶(mov esp,ebp)。接着栈中弹出当前ebp的值(pop ebp)。然后跳转EIP中存储的上个函数的返回地址(retn),回到前一个栈帧中(上一个函数中)删除返回地址行(add esp 4)。到此栈被完全撤销。至此一个栈从建立到撤销的全部过程已经完成。我们除了关心一个栈的创建和消亡,更关心的就是栈是如何传递返回值和参数的。下图是re_choose的反汇编图:清楚的解释了,在栈中是如何传参和返回值的。
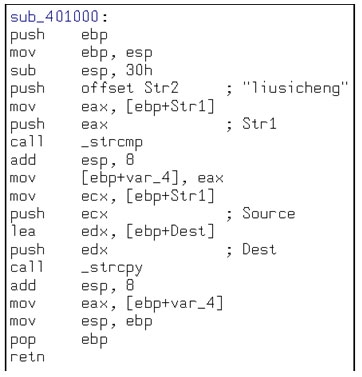
注上图中 var_4= -4 、str1 = 8
main函数从 callsub_401000这句开始,创建子函数re_choose的栈帧,开始也是和main一样的栈创建过程。直到执行到 mov eax,[ebp+str1],这句就是大家最关心的传参。在栈中固定不动的是栈底(ebp)。利用栈底为坐标向高位内存移动8个字节取值。取到存在main中的input。放入eax寄存器中传入re_choose用于计算。同样的机制看后半段从re_choose中(mov eax,[ebp+var_4])取栈底向低地址偏移4个字节的内容。存在eax中,main把eax值存入ebp-404(mov [ebp+var_404],eax)这个地址中用于后续的判断。至此栈的基本结构基本操作已经介绍完毕。栈缓冲区溢出的根源和栈的自身结构密切相关。正是由于栈中数据是先存入的在内存高地址,后入的在内存低地址。所以给了后入的机会,一旦超过栈原本分配的长度则会直接覆盖原先存在内存高地址中的数据或指令。从而带来不可预知的结果。
至于函数的参数传入的顺序是从左到右还是从右到左(局部变量int a,b 是先压a还是先压b),函数返回时恢复栈平衡是让母函数作还是子函数作。这部分和函数调用约定相关,主要的调用约定分为,_cdecl、_fastcall和_stdcall。一般VS默认采用 _stdcall和windows api保持一致。stdcall规则要求:参数从右向左压。(int a,b 先压b)。函数退出的时候自己清理栈中的参数。(图中经常会看到一个参数后面没用直接被add esp 4了)
栈溢出利用原理
由于栈中存储数据和内存方向相反,导致很容易出现后面的数据覆盖前面的数据。最终改变程序。改变的结果从漏洞攻击角度分为2种:1改变程序逻辑,绕过一些判断使得某些限制无效。2.直接劫持程序运行攻击者的攻击代码。
1.改变程序逻辑,还是上面的例子。上面的例子中假如liusicheng这个预设的密码是某银行的密码,通过密码检查后可以获取该密码保护的敏感信息。那么攻击者要想通过密码检查,要么输入正确的密码,要么就需要改变程序流程(输入错的密码但是还能走回对的分支)。为了达到这个目的,我们寻找下choose的地址(re_choose的返回值),看re_choose的图发现局部变量空间是0x30也就是48个字节。在低地址的应该就是用于溢出的buffer在最靠近栈底的4个字节的应该是result的地址,也就是choose取值的地址。result的地址是0012FB6C(由于input输入的是qwe所以返回值是1)值是1,此时密码验证过不去。看低地址的0012F840这个就是字符串buffer。buffer会拷入输入的input值。buffer里面存储的就是657771(win是小端字节序所以全是反的也就是qwe)。到这里,如果想让密码验证通过,就需要修改0012FB6C的值。除了输入正确的密码外,还可以尝试输入过长的input,让input向buffer拷数据的时候造成Buffer缓冲区溢出,用溢出的值覆盖掉在0012FB6C的值,把值修改成希望的0(0就表示通过密码验证了)。
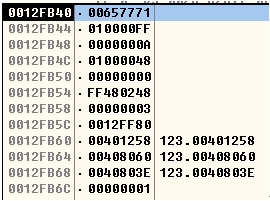
buffer占44个字节也就是input需要至少输入44个字节来占满buffer,然后再输入的字节将会覆盖result。修改choose的值,进而改变程序流程。由于这是字符串最后会有一位null所以咱们输入44个w来占满buffer把null挤到result中覆盖原来的1.
输入43个w

没有缓冲区溢出12FB6C未被修改
输入44个w达到缓冲区溢出
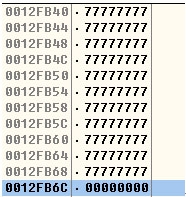
12FB6C正好被结束符null覆盖掉从1改成0。最终跳转到密码验证通过的支路。至此完成绕过密码检验的全部步骤。这是缓冲区溢出的最基本用法。其实方法2只是在方法1的基础上更进一步而已。
2.直接劫持程序运行攻击者的攻击代码。既然能通过缓冲区溢出覆盖掉一些关键变量导致函数流程被改变。如果继续向下溢出那么就有可以覆盖函数返回地址。改变函数返回地址到攻击者需要返回的地方。本程序可以设计成在buffer内存入一个脚本,然后用w填满buffer中脚本到返回地址这中间的空缺。最后把buffer的首地址覆盖到函数返回地址。让函数返回时,返回到buffer的初始地址,执行buffer内存储的脚本。
为了达到这个目标,首先要确定函数返回的地址和buffer的地址。前面已经得到了buffer的地址,看图可知函数返回的地址。也就是需要从溢出点buffer到函数返回地址之间覆盖我们的信息。函数返回地址在12FB74buffer初始地址是12FB40,咱们需要覆盖掉这56个字节。

构造一个shellcode(介绍shellcode不再本文范围之内)+填充数据+0012FB40。这样当函数发生retn时,不会跳到0041064,而是跳转到设定好的0012FB40中。后面就会按步执行存储于0012FB40中的shellcode。至此就完成了整个溢出过程,通过缓冲区溢出劫持整个程序的方法除了这种直接的覆盖返回值地址外,还有覆盖SEH。
SEH
SEH是windows下的异常处理机制的重要数据结构(c++的_try的异常处理其实本质就是调用的SEH)。保证windows在出现各种错误操作后给函数或系统一次call back的机会。SEH结构非常复杂,这里只说和缓冲溢出有关的部分。每个SEH包含两个DWORD指针:SEH链表指针和异常处理函数句柄,共8个字节存储于栈中。当线程初始化时,会自动向栈中安装1个SEH,作为线程默认的异常处理。如果程序调用了-try()等异常处理机制。编译器就是向当前函数栈中安装1个SEH来处理异常的。栈中同时可以存在多个SEH。整个栈中的SEH通过链表指针形成一个贯穿整个栈的单向链表。当异常出现,操作系统中断程序,沿着整个SEH链表依次查询看是是否有能处理这个异常的SEH。如果程序加载的SEH都不能处理,则会到系统级的SEH,由他探出错误窗口,强制关闭程序。
SEH存在于栈中,所以栈缓冲区溢出有机会覆盖掉SEH。和覆盖返回地址一样,如果覆盖后异常处理的函数入口被修改成上面的buffer的入口那么就可以,通过shellcode+填充数据+buffer地址的手法。达到攻击的目的,但是要注意的是需要在填充数据中触发异常来保证SEH被触发。
至此windows下缓冲区溢出的主要原理已经介绍完毕。安华金和数据库安全实验室将在下一篇文章中用一个oracle10g上的缓冲区漏洞来和大家继续分享栈缓冲区溢出这一话题。
标签: 安华金和, 数据库安全, 数据库缓冲区溢出, 缓冲区溢出