什么是命名数据网络 (Named Data Network,NDN)?
为了适应发展迅猛的互联网数据,引发了对未来网络的研究热潮,国际上主要形成了“演进式”与“改革式”两种研究路线。
· “演进式”路线——不断完善和改良现有 IPv4 核心网络,最终平滑过渡到以 IPv6 协议为核心的互联网,其核心架构很难修改,新的功能只能通过在现有架构顶层以“打补丁”的方式实现,难从根本上解决传统互联网在移动性、安全性及可扩展性等方面的不适应性。
· “改革性”路线——重新设计全新的互联网体系架构,以替代 IP 核心网络,满足未来互联网的发展需求。这方面的代表是美国的 FIA、FIND/GENI 项目。
命名数据网络(Named Data Network,NDN),是美国国家科学基金会(NSF)于2010 年在未来网络架构(FIA)项目中重点资助的四个项目之一。
其目标是替代现有的以 IP 为核心的网络体系架构,“以数据为中心”将通信范式的重点从关注于“where”(地址、服务器、主机)转变到“what”(通信的内容)。以对数据命名的方式代替位置(IP地址),将数据转变成网络的第一要素。
在命名化数据网络中,不在意数据包的源地址和目的地址,只关注内容本身,通过内容的名字直接寻址。
体系架构如下图所示。
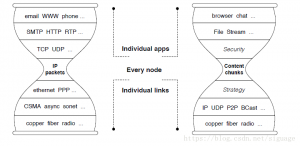
NDN 体系架构(图源:简书帐号-johnosnfan)
NDN 网络的基本功能包括:
· 请求者驱动的数据传递
· 内置的数据安全
· 网络缓存
请求者驱动的数据传送可通过设置数据包转发状态实现,加之网络缓存功能,使得 NDN 网络支持数据多播传递与内容分发,从而实现均衡数据流的拥塞控制、多路径查询数据及便于移动和延迟容忍通信。
命名数据网络所面临的安全威胁
在 NDN 网络中,数据包携带的消息包含了重要内容,数据泄露的风险面明显扩大。
名字隐私:
名字隐私是由可读的内容名字与内容本身之间的语义相关性造成的。
NDN 网络是基于名字查询和路由的,内容的名字不仅可视而且一般要与内容相关,内容名字愈是与内容本身语义相关,名字愈能泄露关于内容的很多信息,攻击者通过监控用户的请求能够推断出关于用户的敏感信息。
内容隐私:
NDN 网络允许任何知道一个名字的实体检索相应的内容。
对公开共享的非机密信息,如果使用对发布内容加密的方式,则只有获取密钥的用户才能解密,将会减弱网络缓存特性,降低资源共享效率。
签名隐私:
NDN 网络的主要目标是解耦内容与内容所在的位置,允许请求者从邻近的缓存查询数据。
为了确保获取的内容是可信的,NDN网络架构设计时使用数字签名来确保源认证与完整性,然而签名需要是公开可验证的,数据包中要携带有内容发布者的 ID 等相关验证信息,攻击者通过验证信息就能够获取发布者的身份等敏感信息。
缓存隐私:
NDN 网络通过缓存减少了通信量、改进了传输速度,然而由于频繁地缓存请求的内容,攻击者通过计时攻击可以推断别人访问的内容位置。
如何保护命名数据网络中的数据安全?
世平信息提出一种隐私数据保护方案:
基于【攻击者和隐私保护的建模、匿名操作、通用可组合安全理论、博弈论】等理论和技术手段,实现数据发布和共享的敏感信息智能清洗、隐私信息泄露的风险评估以及隐私保护系统的效能评估,为NDN网络中的数据安全问题提供解决思路。
01 攻击者和隐私保护的建模
根据攻击者的分类(链式攻击者和概率攻击),研究现有的k-匿名(k-Anonymity)、l-多样性(l-Diversity)、ε-差分隐私(ε-Differential Privacy)等传统隐私保护的建模方法。
通过博弈论建立攻击者和数据发布方的博弈论模型,根据双方的效益函数,即攻击者需要满足某“置信下界”(Confidence bound)所需要的代价,以及数据发布方需要满足抵御多种不同攻击方式下的代价,使用信息安全风险评估理论,对双方的代价作出定性和定量的估计。
通过求解博弈论模型,找到符合双方利益的纳什均衡,实现应对不同用户需求以及不同数据的动态需求情况下,数据发布方能够自适应地采用最理性的隐私保护方案。
02 匿名操作
数据发布前,通过一系列的匿名操作对原始数据进行修改,以达到用户隐私不被泄露的目的。
目前存在的主要匿名操作有:
· 概括(Generalization)
· 抑制(Suppression)
· 解构(Anatomization)
· 置换(Permutation)
· 扰乱(Perturbation)
采用不同的匿名操作会对隐私保护性能指标产生不同的影响:
· 通过语义学及前面提到的数据敏感度度量机制,设计快速高效的数据分类技术,实现对敏感数据的概化和匿名操作;
· 利用同态加密等方法,实现对于数据关联性的高效的解构和置换方法;
· 分析不同的分布函数作为扰乱随机噪声时对整个系统性能的影响,建立针对不同数据和安全需求的噪声库;
· 最后,使用通用可组合安全理论,建立匿名操作方案,从计算复杂度、时间复杂度、额外开销等方面提高系统性能。
03 数据可用性
采用建立信息度量参数的技术路线来对数据信息在发布前后的可用性进行评估。通过对现有信息可用性度量机制如信息损失量(Information Loss)、分类度量(Classification Metric)、分辨度量(Discernibility Metric)等研究,以概率论和统计学理论为依据,建立对数据发布前后数据的可用性数学模型,获得数据可用性评估方案。
04 隐私信息泄露的风险评估
应用信息安全的风险评估理论,研究隐私信息从采集到最后给出风险评估指数的整个流程,将定性分析和定量分析结果整合,根据用户隐私保护需求给出评估结果。
如果符合用户的隐私保护需求,同时指出存在的隐私安全威胁。
05 隐私保护系统的效能评估
通过现有的隐私保护模型如k-匿名、差分匿名等方法,结合已经建立的攻击者和隐私保护方的博弈论模型,计算系统的匿名成功率等。
将上述指标与一般系统效能评估参数结合,并结合隐私数据的可用性参数,建立三维的系统效能参数空间,为用户提供弹性的隐私保护评估机制。
参考文献:[1]于晔,李联峰,郭红纲.《新一代互联网NDN面临的挑战及脆弱性分析》[J].《信息安全与通信保密》,2014年,03期.