大家好,给大家介绍一下,这是我男神@VAGE

吕海波
国内知名数据库技术专家、数据架构师
曾任阿里/京东/ebay高级专家、首席DBA
Oracle传奇技术大师
ITPUB Oracle 管理版版主
噔噔噔,吕大主笔数据库系列文章——《数据库传奇》,从数据库选型例子入手,介绍SQL和NoSQL数据库的特点,把所有数据库的特性、适用范围,加上一些业内故事、传说,写上一遍。
本着“一般不出手,出手就是大作”的原则,文章更新不定期。本期推出《数据库传奇》第一章:Digg启示录----你选对数据库了吗?
---------------------------------------------------------------------------------------------------------------------未来的世界是属于数据的,而数据则存储在数据库中。数据库,无疑是企业所有应用的基石。数据库种类有很多,你选对数据库了吗?美国有一家互联网公司,Digg。创办于2004年,又叫掘客,就是个新闻网站,但不同于传统的新闻门户,Digg根据用户的行为(差不多就是评论、点赞之类的),决定那些新闻显示在首页。这在当年叫做Web2.0,由用户决定显示什么东西,火的不得了。它开创了Web2.0概念,首创“用户创造内容”先河,在美国互联网公司中,曾一度排名第24位,其地位相当于中国的知乎和豆瓣。Google曾想花5亿美元收购它,但被其创始人拒绝。Digg之前一直在使用MySQL数据库,直到遇到了这个人约翰·奎恩(John Quinn),曾在Oracle但任工程师,是数据库老鸟一枚。2010年时,Digg发展一路高歌猛进,相应的,数据库的压力,自然也是高歌猛进。纠正一下,“分库分表”其实不是学术上的叫法,专业术语叫“数据分区”,也就是Partition。不过,咱们也不是要讨论特理论的学术问题,什么CAP之类的。咱们还是沿用“分库分表”的叫法。分库分表可不是你说想分就分的,涉及应用改造、一致性、数据同步等等一系列复杂无比的问题。业内第一家分库分表的公司,是美国电商ebay。ebay的架构师早在2003年,率先提出了分库分表的方案,并成功实施。不过,要说影响力最大的,还是阿里巴巴。
阿里巴巴利用分库分表技术,实现了超大规模分布式数据库,将绝大部分数据移到了开源的MySQL,或自研的OceanBase(当然,仍有少量关键数据在Oracle)。并且多年来成功应对超高并发的“双十一”,让美国同行都为之惊讶不已。其推出的名词“去IOE”,甚至上了央视某新闻频道。所以从影响力上说,阿里巴巴让分库分表成为了专有名词,牛。转过头再说约翰·奎恩。2010年初,奎恩此时已经在Digg高居VP(副总裁),并刚刚担任CTO不久。Digg的数据层解决方案,使用的是MySQL,本来也是分库分表的,只是分的不彻底,面对数据库压力逐步增大的情况,需要进一步的、更加彻底的分库分表,这就要求对应用进行大范围的改造。2010年,彼时国内NoSQL如清风拂面,但在太平洋对面的美国西海岸,世界第一大湾区——旧金山湾,美国的高科技产业聚集地,也就是硅谷,NoSQL已如飓风般摧枯拉朽。奎恩显然没有经受住飓风的吹拂。2010年初,圣诞节的假期刚结束,Digg的员工意犹未尽地回到工作岗位,去MySQL换Cassandra的工作就正式开始了。Digg并不是第一家尝试Cassandra的公司。Cassandra,作为当年炙手可热的NoSQL数据库,诞生自社交巨头FaceBook,而后另一个社交巨头Twitter也采用了Cassandra。当年可谓是最成功的NoSQL数据库。有别人家的成功经验,再加上自家数据库团队的充分测试,奎恩终于决定动手了。根据数据库团队的测试结果,Cassandra性能更快,而且扩容更加方便。打动奎恩的,正是扩容方便。比如,有一个集群中有20台主机,现在由于性能不足,需要扩展到30台。基于MySQL的分布式当然也可以扩容,但每次扩容都是伤筋动骨的大动作,搞的数据库团队人困马乏。相比之下,性能表现更加出色的Cassandra,扩容是非常方便的。有了这个特性,数据库压力增大多少,就扩多少台主机,甚至还可以减少压力不高集群的主机数量,这才是真正的动态扩展啊。有了Cassandra,工作更轻松。为什么MySQL的分布式扩容复杂,而NoSQL的Cassandra分布式扩容就简单呢?这个问题并不容易回答,我抖胆为大家解读一下。(以下满满都是干货)这个问题,是公众认为“NoSQL是分布式、SQL型数据库不是分布式”的重要原因之一。分布式,最关键的部件是“路由”,它相当于“传达室”。
假如这家单位有100间办公室,你要找老张,但你并不知道老张在哪儿,你先到传达室问了一下:“同志,老张在那个办公室”。传达室告诉你,“老张在二楼左边第二个办公室。”然后,你去找老张办事。这里,传达室就是一个“路由”,或叫做“转发器”。他并不能为你办事,他只是告诉你,你要找的人在哪儿。分布式数据库中的路由部件同样,它不能执行你的操作,他只是告诉你,你要操作的数据应该在哪里,哪个sub database(子数据库)可以完成你的操作。更进一步,为了优化人员结构,这家单位裁撤了传达室,设置一种规则,根据规则一下子就可以算出要找的人在哪里。比如说,有一家单位
(对,就是白宫,看图片一点都不宏伟)假设一共有30个办公室,规则如下,按人名笔画数,除以30,余数为几,就在几号办公室工作。
比如,总统先生,唐纳德·特朗普,应该在几号办公室?

唐纳德·特朗普,笔画数一共64,除以30,余数为4。
总统先生在4号办公室办公。
前总统奥巴马呢,贝拉克·侯赛因·奥巴马,笔画数一共68,除以30,余数为8,按照我们的规则,前总统先生在8号办公室。
怎么样,这样一来,每次你去白宫找人办事,只需要根据人名笔划数计算一下,就知道要找的人在哪里了。通过这种方式,不再有“传达室”,可以少花纳税人的钱。路由方式,则变成了“规则”(即笔划数除以30取余)。
规则式路由,是分布式数据库最常采用的。而“笔划数除以30取余”这样的规则,则属于HASH规则类。
在IT领域中,根据某种确定的方式,将一个数字进行计算,得到另一个数字,这就是HASH算法的本质,对HASH在这里不必深究,以后再专门开篇文章好好讲讲这些著名的算法。
我们例子中的HASH规则,像不像一样生活中常见的东东,给你三秒想一下,是什么:

没猜出来,对吗!没关系,翻开一本新华字典,它的目录编排方式,就是一种HASH规则。
Oracle、MySQL等SQL型数据库的分布式就是这样,基于某种HASH规则,将数据存储在某一个Sub Database(子数据库中)。操作数据时,同样根据HASH规则,计算得出数据存储在哪一个Sub Database中,然后到相应的Sub database中执行操作。
说白了,就是先查一下目录再翻书。
这里有一个问题,比如随着人员的扩展,白宫的办公室不够用了,预算部门决定明年新增1间办公室。这就是分布式数据库的扩容了。也叫横向扩展。
办公室数量增加到31之后,原来的规则“笔划数除以30取余”,要改为“笔划数除以31取余”了,除以30,要改为除以31了。因为现在办公室数量已经由30增至31了。
总统先生唐纳德·特朗普的笔划数是64,基于原来的HASH规则,是在4号办公室,但现在,他应该在2号办公室。64除以31余数是2了。
前总统奥巴马呢,贝拉克·侯赛因·奥巴马,笔画数一共68,除以31,余数为6。前总统先生的新办法室在6号。
不但总统先生,副总统、各位参赞、秘书,所有人的办公室都变了。除以30取余,和除以31取余,结果将大不相同。
这就是为什么分布式数据库扩容这么难了。本来30个子库,扩展到31个子库,所有数据要全部改变一下它所属的子库。所有数据都要辗转腾挪一边,这当然是个大工程了。
而Cassandra有一个非常好的特性,它的分布式是按照一致性HASH算法,计算数据应该存储在哪个Sub Database(子数据库)。一致性HASH,英文名称Consistent Hashing。它是普通HASH算法的修正,目的就是为了解决HASH算法在扩容(或缩容)时,要对所有数据重新计算HASH值的问题。
说到Consistent Hashing,不能不上一张图:
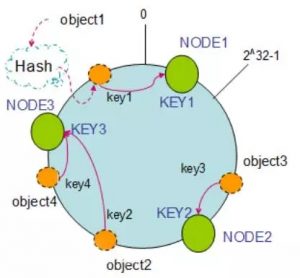
所有介绍Consistent Hashing的文章,都必须祭出这张图,才能显得自己专业。我们就不照这个图解说了,来个简单的。
这次咱们又要到五角大楼找人了。假设五角大楼只有5个办公室,分别分布在5个角上。

这次又要怎么安排办公室呢?姓名笔画数除以5取余吗?先别急做除法,虽然目前五角大楼办公室数少,但它目标宏大:

据说,很快就会发展到30间办公室。可目前只有5间,没关系,要面向未来吗!
具体怎么做呢?先把5间办公室的编号改的大气点:

1号办公室就不叫“1号”了,为了面向未来,直接叫“6号办公室”。然后,2号改为12号,3号改为18号,以此类推。好了,现在五角大楼已经有30号办公室了。 看图片,没有1、2、3……直接蹦出来个6,然后是12,等等,这多别扭啊。没关系,可以发扬无产阶级空想精神,假想在6号前面,有1、2、3、4、5号办公室存在。当然,它们现在还不存在,可以称它们为虚拟办公室,如下图:
看图片,没有1、2、3……直接蹦出来个6,然后是12,等等,这多别扭啊。没关系,可以发扬无产阶级空想精神,假想在6号前面,有1、2、3、4、5号办公室存在。当然,它们现在还不存在,可以称它们为虚拟办公室,如下图:
现在,每名五角大楼工作人员,按姓名笔画数除以30其余,余数为1到6的,在6号办公室(原1号)。余数为7到12的,在12号办公室(原2号)等等,以此类推。除以30其余,计算出的是虚拟办公室编号,只要顺时针向后找,找到的第一个实际办公室,就是真正所在的办公室。如果两位总统先生到了五角大楼,应该在哪个办公室呢?现总统先生唐纳德•特朗普的笔划数是64,除以30取余是4,也就是虚拟办公室编号为4,顺时针向后找,第一个大于4的实际办公室是6号。所以特朗普在6号办公室。 而前总统贝拉克•侯赛因•奥巴马先生,笔画数一共68,除以30取余是8。
而前总统贝拉克•侯赛因•奥巴马先生,笔画数一共68,除以30取余是8。
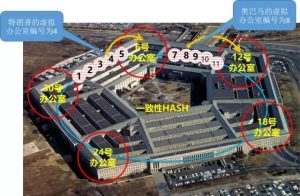
如上图,从8开始,顺时针向后找,奥巴马在12号办公室。
这就是一致性HASH的计算过程。现在,让我们把背景碍眼的五角大楼图去掉:
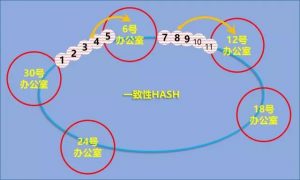
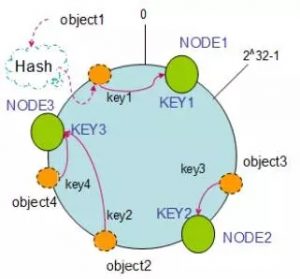
(特别说明:文中虚拟办公室和Cassandra中的虚拟节点并不是一个概念)。
相较普通的HASH,一致性HASH的优点是扩/缩容的时候影响小,这一点如何表现出来的呢?看下图:
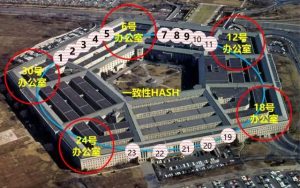
现在要在18到24之间增加一间实际办公室。本来19到23号虚拟办公室的人,都按排在24号实际办公室办公的。或者说,19到23,属于24。
假设21变为了实际办公室:
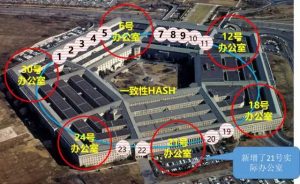
原来都属于24号,19到23,又如何安排呢?很简单啊,原则一样,“顺时针向后找,第一个实际办公室就是最终位置”。按照新的办公室数量,22号、23号虚拟办公室,还属24号实际办公室不变。19号、20号则属于新的21号办公室。重点是,在18和24号办公室之间新增一个办公室,只影响在24号办公室中的人。其他实际办公室的人不会有任何变化。这就是一致性HASH的独特之处。在只有5个实际办公室的情况下,使用普通HASH算法,增加一个办公室,影响所有人。所有人都要重新计算位置。一致性HASH算法,只有五分之一的人受影响。我们把“办公室”换成节点,把“人”换成数据,再把实际办公室数量增大。如果有500个节点,节点扩容时,使用一致性HASH算法,只有五百分之一的数据受影响。怎么样,节点数量一多,扩容或缩容受影响的数据就越少。而普通HASH算法,无论有多少节点,每次扩/缩容都要影响全部数据。因此,采用了一致性HASH的Cassandra的,理论上扩/缩容的影响会比较小。正是这个特性,深深的打动了奎恩。在奎恩的推动下,Digg的应用开发部门,重写了所有的应用代码,以适应NoSQL的Cassandra数据库。不再有SQL,这会使应用的开发更加复杂,但好处也是显而易见的。横向扩展(也就是扩容)更加方便、更好的性能……故事继续。至2010年8月,Digg的技术团队完成了这次购模浩大的重构。底层数据库,成功换为了NoSQL的Cassandra。从年初到8月份,大半年的时间,对于替换所有底层数据库这样的大动作来说,还算是快的了。故事到这里,是不是听起来像“从此公主与王子幸福的生活在城堡中”?
但可惜,幸福总是短暂的,奎恩很快就会明白这一点。虽然当时,他还不明白。完成了这次基础数据库改造,奎恩已经变身为硅谷科技界红人,他相当于在硅谷发动了一场去IOE的运动。时间到了2010年9月份,“去M”(去MySQL)才刚一个月。在这一个月内,Digg最繁忙的部门,是客服部。自从改版之后,Digg的网站一直处于非常不稳定的状态,各种功能频繁出错,很多时候站点干脆就没法访问。怒火高涨的用户打爆Digg的客户电话,然而,既使把客服人员爆打一顿,仍然没什么卵用,网站依旧频繁出错。最危险的情况出现了,大量用户弃Digg,开始玩起了类似的Reddit。想象一下,豆瓣由于网站经常打不开,大量用户弃豆瓣转向知乎。(免责声明,此处只是比喻,此种情况并没发生在豆瓣和知乎之间)。9月份时,Digg的访问量跌到了谷底。而竞争对手Reddit的访问量再创新高,并在12月份超过Digg,从此把 Digg 远远地甩在了后面,绝尘而去。 
有些东西,失去了就再也不会回来。Digg就是这样,后来又经历了一系列的调整,Digg才终于明白,应该让合适的场景使用合适的数据库。但一切都为时已晚,机会窗口已经关闭。Digg勉强维持了将近两年,到2012年7月,被Betaworks 收购,收购价仅为 50 万美元。与颠峰时期 Google 接近 5 亿美元的收购意向相比,其缩水程度令人瞠目结舌。这么大的错误,总要有人背锅,约翰·奎恩自然难逃其咎。在成功改换数据库一个月后,也就是当年9月份,奎恩就从高点跌到低点,面对愤怒的用户,和频繁出错的网站,奎恩不得不黯然离开Digg。但数据库团队的大部分人都没动,虽然数据架构的负责人是最直接的责任人。但由于接下来数据架构的调整还是需要他们,这个时候辞退数据库部门的重要技术人员,不单于事无补,反而更加雪上加霜。数据架构人,只是结合Digg的场景,对Cassandra进行了测试。测试是大量的、复杂的,而且耗时一定不短,最终得出了相对于MySQL,Cassandra性能更佳、扩容更方便的结论。但实际应用场景的复杂度,是测试无法模拟的。而且,NoSQL并不是解决所有问题的银弹。幻想有一种方法,可以解决一切问题,这本身就违背了系统架构师的基本法则。“合适的场景,使用合适的数据库”,才是真正的王道!
一个“惨痛”的数据库选型的例子,告诉我们,数据库选择的重要性。那如何选择适合的数据库,SQL和NoSQL数据库各有什么特点?欲知后事如何,请听下回分解!












