2015年10月8日,有幸参加了Apache Kylin Meetup @上海 的活动,听到了主创人员的精彩演讲(http://mp.weixin.qq.com/s?__biz=MzAwODE3ODU5MA==&mid=209680896&idx=1&sn=f1e73acb601134664b4dc88625af7783&scene=23&srcid=1010riPU73wQar7TcUE9rrk1#rd),同时也非常感谢主办方请来了Zeppelin(zeppelin.apache.org)项目的负责人来讲解,使得收益匪浅。今天,我就针对Zeppelin的可视化功能进行一些见解,希望能够给需要的朋友起到一点抛砖引玉的作用。当然,Zeppelin的功能不止这么多,更多更强的是可以用spark神器完成你的大数据分析。
咱废话不多说,直接进入正题。客观让您久等了,马上上菜了。
安装Zeppelin
到官网下载二进制包(http://zeppelin.apache.org/download.html),当然,你要是愿意,可以下载源码自己编译。
wget http://apache.fayea.com/incubator/zeppelin/0.5.0-incubating/zeppelin-0.5.0-incubating-bin-spark-1.4.0_hadoop-2.3.tgz
tar -zxvf zeppelin-0.5.0-incubating-bin-spark-1.4.0_hadoop-2.3.tgz
至此,安装完毕,是不是非常简单?
运行Zeppelin(启动/停止)
启动Zeppelin
bin/zeppelin-daemon.sh start
停止Zeppelin
bin/zeppelin-daemon.sh stop
是不是超级简单?打开浏览器: http://192.168.1.230:8080,界面就出现了。

什么是Interpreter?
Zeppelin Interpreter是一门后端语言。例如,要在Zeppelin使用Scala代码,你需要scala解释器(interpreter)。简单说,你要运行MySQL代码,你需要MySQL解释器,这个需要一些小小的开发。
开发MySQL Interpreter
编译代码
去我的github下载源码并且编译,这个很重要!!!
git clone https://github.com/jiekechoo/zeppelin-interpreter-mysql
mvn clean package
部署二进制包
假装你的zeppelin安装在 /opt/zeppelin目录
mkdir /opt/zeppelin/interpreter/mysql
cp target/zeppelin-mysql-0.5.0-incubating.jar /opt/zeppelin/interpreter/mysql
# copy dependencies to mysql directory
cp mysql-connector-java-5.1.6.jar log4j-1.2.17.jar slf4j-api-1.7.10.jar slf4j-log4j12-1.7.10.jar commons-exec-1.1.jar /opt/zeppelin/interpreter/mysql
cp conf/zeppelin-site.xml.template conf/zeppelin-site.xml
vi conf/zeppelin-site.xml
在zeppelin.interpreters 的value里增加一些内容 ,org.apache.zeppelin.mysql.MysqlInterpreter 如下所示
<value>org.apache.zeppelin.spark.SparkInterpreter,org.apache.zeppelin.spark.PySparkInterpreter,org.apache.zeppelin.spark.SparkSqlInterpreter,org.apache.zeppelin.spark.DepInterpreter,org.apache.zeppelin.markdown.Markdown,org.apache.zeppelin.angular.AngularInterpreter,org.apache.zeppelin.shell.ShellInterpreter,org.apache.zeppelin.hive.HiveInterpreter,org.apache.zeppelin.tajo.TajoInterpreter,org.apache.zeppelin.flink.FlinkInterpreter,org.apache.zeppelin.mysql.MysqlInterpreter</value>
重启zeppelin即可
bin/zeppelin-daemon.sh restart
运行MySQL代码
加载mysql interpreter
登录管理界面,Interpreter -> Create, 类似下面的页面,完成点击 Save
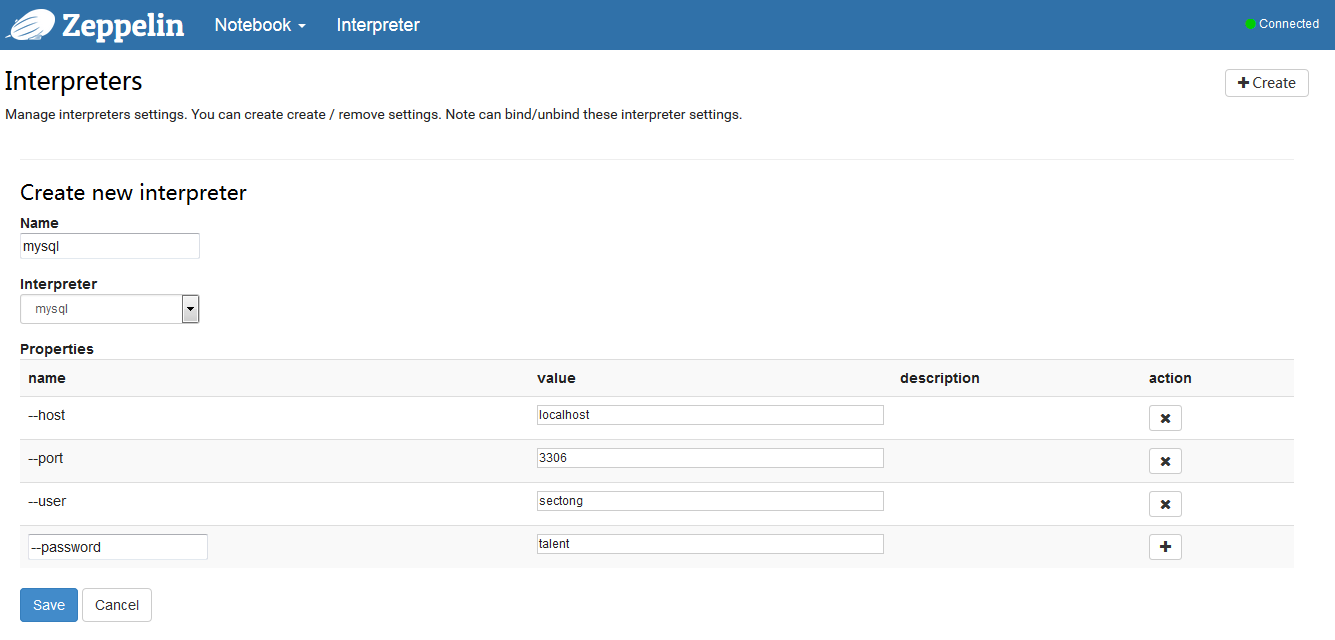
创建 Notebook,完成你的可视化
点击右上角的setting,并且确保mysql被选中,保存Save
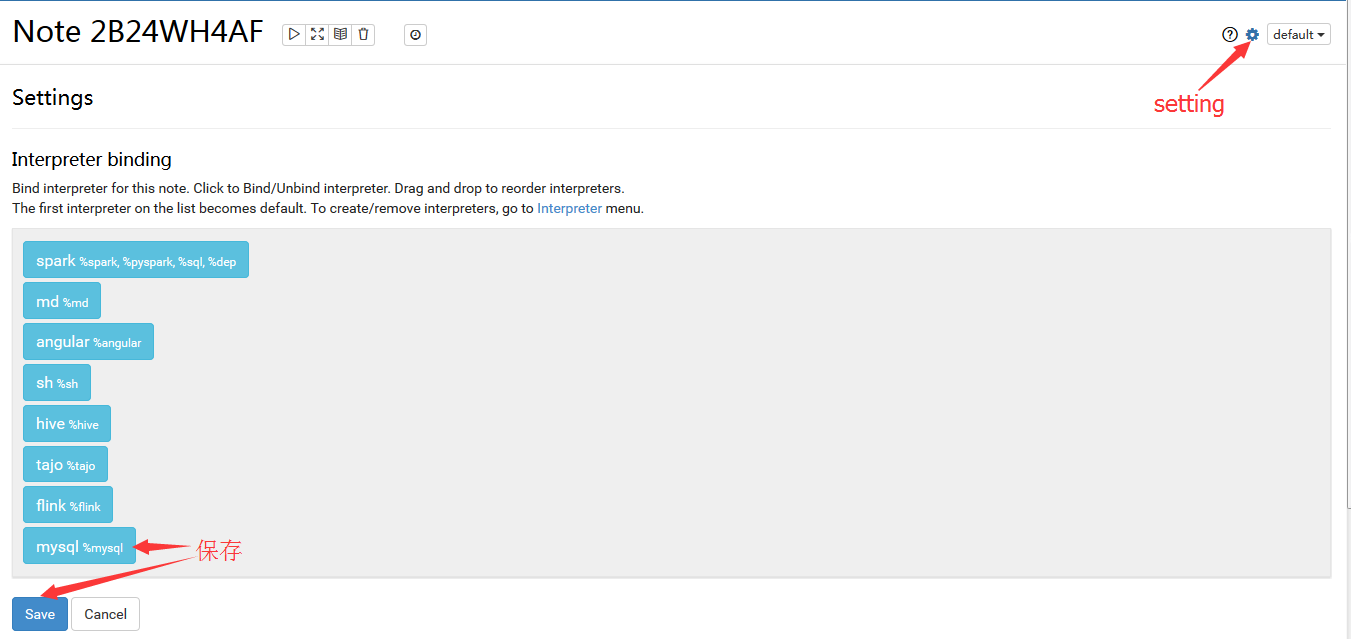
输入你要执行的SQL语句,相信你再熟悉不过了
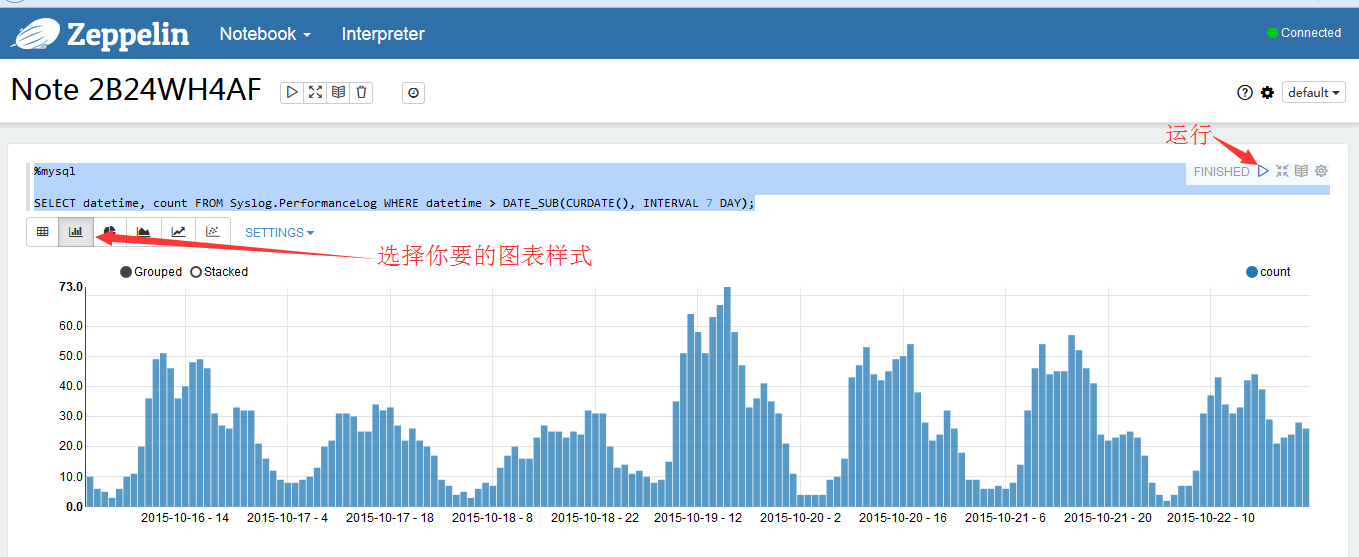
%mysql
SELECT datetime, count FROM Syslog.PerformanceLog WHERE datetime > DATE_SUB(CURDATE(), INTERVAL 7 DAY);
点击运行按钮,结果出现了,是不是很神奇?
可以做成报表模式,更好看更爽了
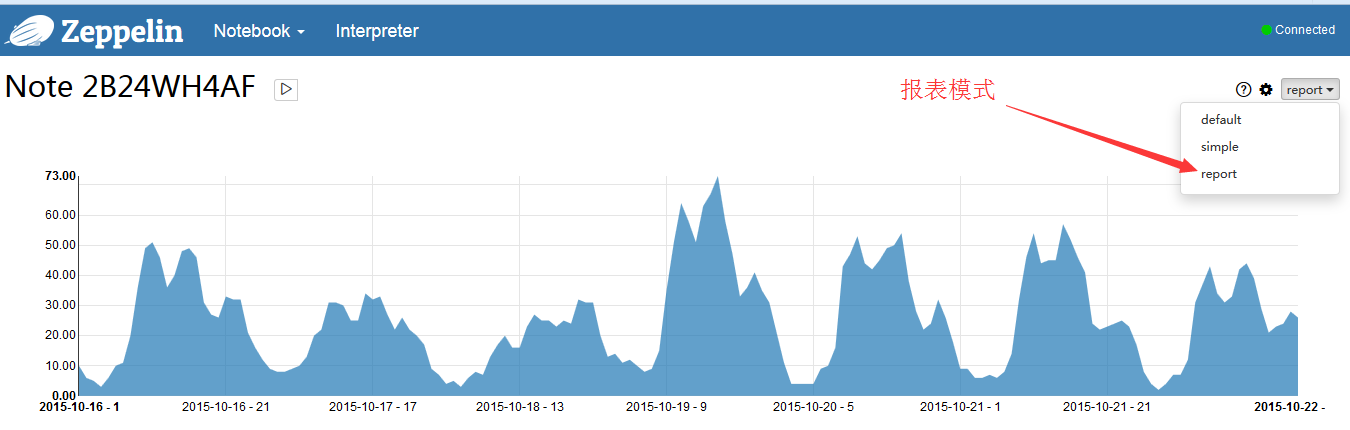
可以在其他地方引用这张报表
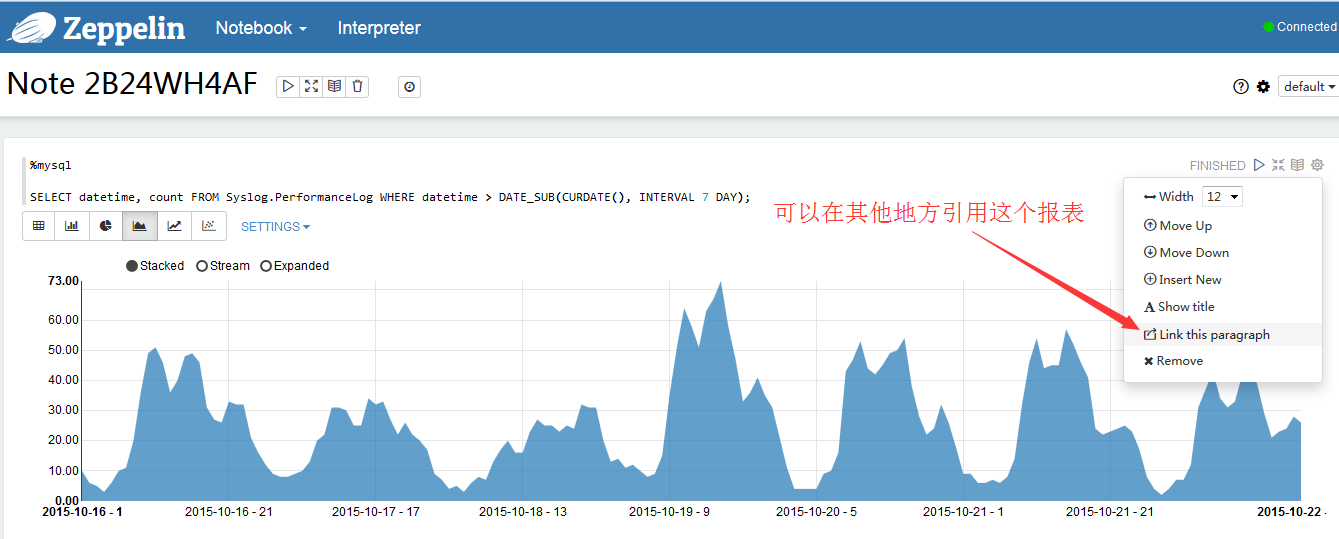
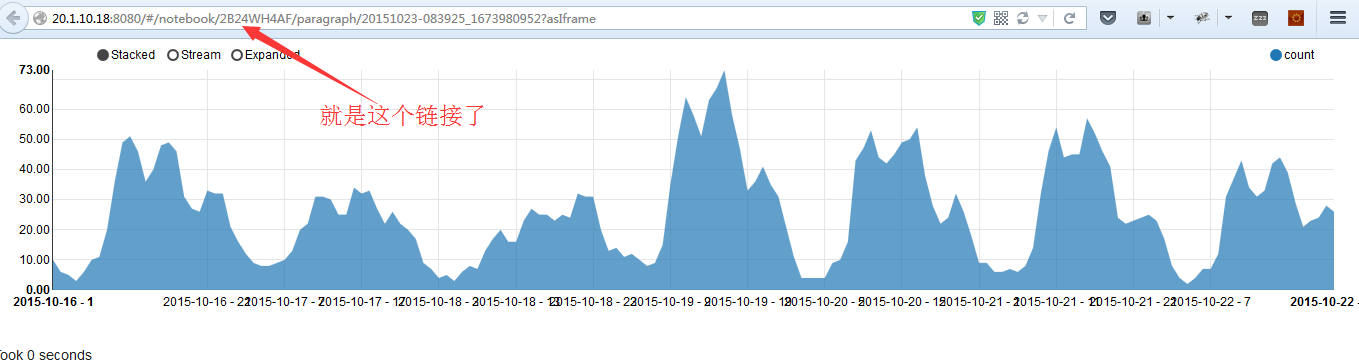
将链接作为框架引入你的代码中吧
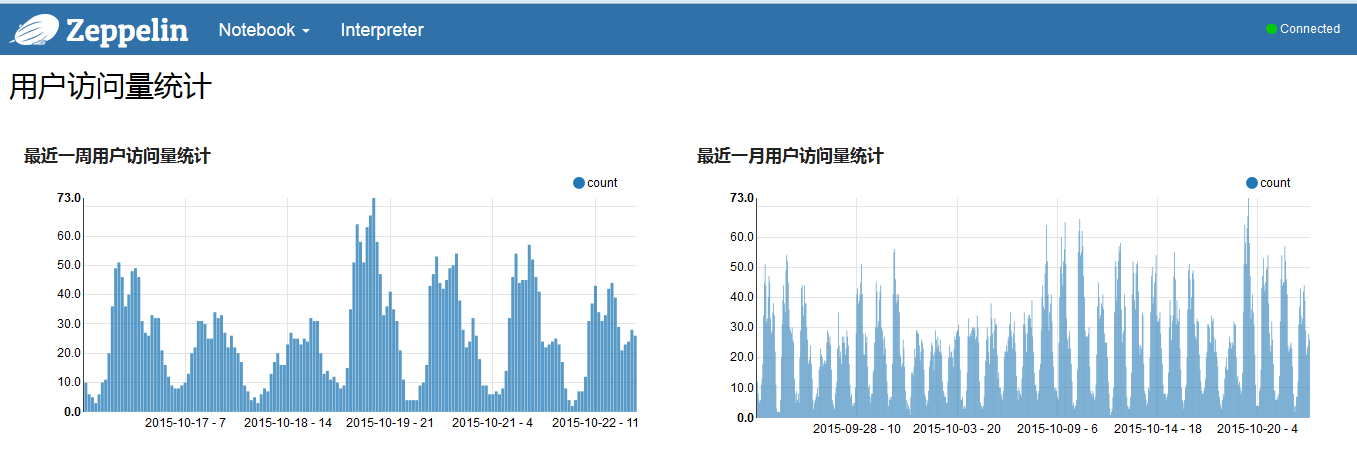
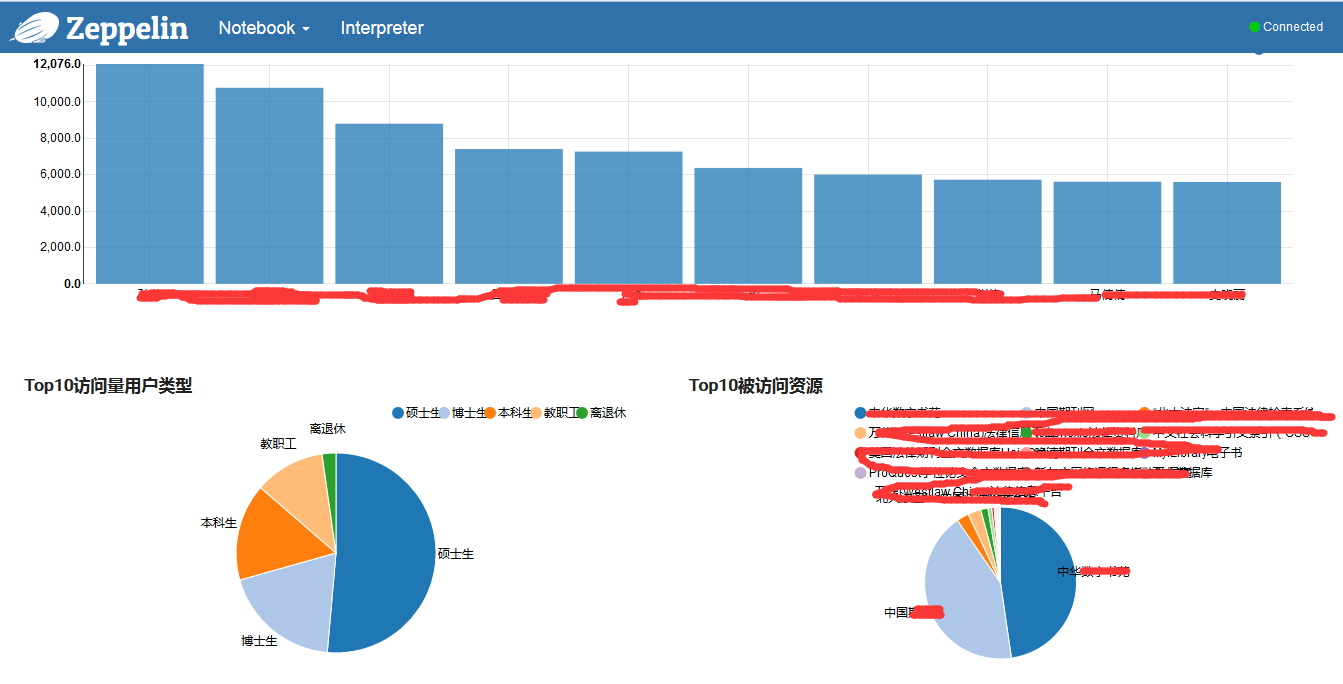
几张效果图
稿源:http://blog.sectong.com/blog/zeppelin_mysql.html