什么是OpenSOC
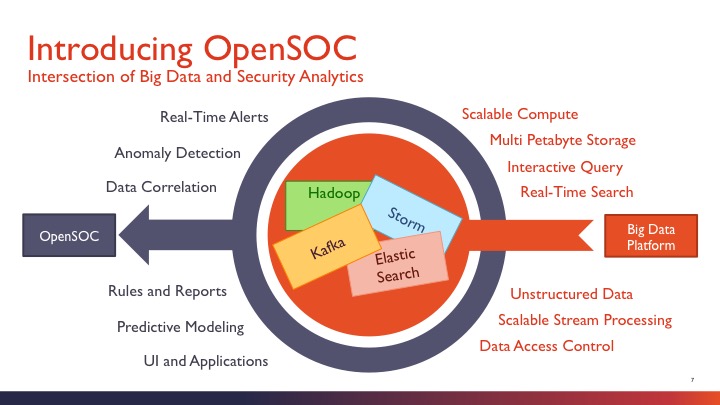
思科在BroCON大会上亮相了其安全大数据分析架构OpenSOC(由Cisco和Hortonworks共同开发),引起了广泛关注。OpenSOC是一个针对网络包和流的大数据分析框架,它是大数据分析与安全分析技术的结合, 能够实时的检测网络异常情况并且可以扩展很多节点,它的存储使用开源项目Hadoop,实时索引使用开源项目ElasticSearch,在线流分析使用著名的开源项目Storm。
OpenSOC是大数据安全分析的框架设计,对数据中心机排放数据进行消费和监控网络流量。opensoc是可扩展的,目的是在一个大规模的集群上工作。
OpenSOC能做什么?
- 可扩展的接收器和分析器能够监视任何Telemetry数据源
- 是一个扩展性很强的框架,且支持各种Telemetry数据流
- 支持对Telemetry数据流的异常检测和基于规则实时告警
- 通过预设时间使用Hadoop存储Telemetry的数据流
- 支持使用ElasticSearch实现自动化实时索引Telemetry数据流
- 支持使用Hive利用SQL查询存储在Hadoop中的数据
- 能够兼容ODBC/JDBC和继承已有的分析工具
- 具有丰富的分析应用,且能够集成已有的分析工具
- 支持实时的Telemetry搜索和跨Telemetry的匹配
- 支持自动生成报告、和异常报警
- 支持原数据包的抓取、存储、重组
- 支持数据驱动的安全模型
是不是很强大?
OpenSOC运行组件包括哪些?
- 两个网卡(建议使用Napatech的NT20E2-CAP网卡)
- Apache Flume 1.4.0版本及以上
- Apache Kafka 0.8.1版本及以上
- Apache Storm 0.9版本及以上
- Apache Hadoop 2.x系列的任意版本
- Apache Hive 12版本及以上(建议使用13版本)
- Apache Hbase 0.94版本及以上
- ElasticSearch 1.1版本及以上
- MySQL 5.6版本及以上等。
据说,能把这个框架跑起来的人不多。
OpenSOC组成部分(核心)
OpenSOC-Streaming:这个库包含了拓扑结构的加工、丰富,索引,及相关的信息,PCAP重建服务,以及其他各种数据服务。可以在GitHub下载:https://github.com/opensoc/opensoc-streaming
OpenSOC-UI:操作界面,日志和网络数据包的分析,显示警告和错误。可以在GitHub下载:https://github.com/opensoc/opensoc-ui
OpenSOC深入剖析
OpenSOC框架是大数据分析框架的衍生
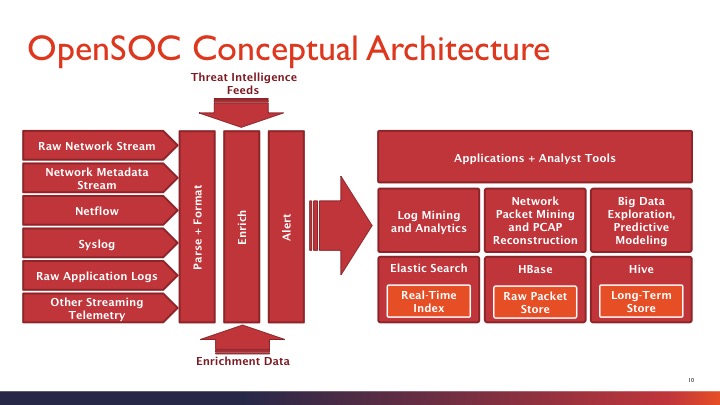
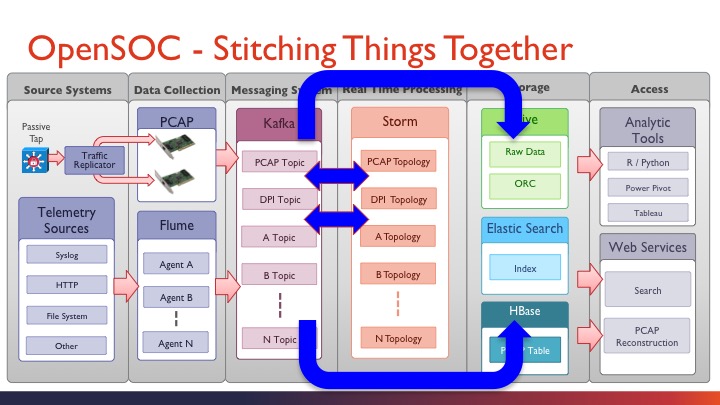
先来看看OpenSOC概念性框架,总体来说,就是分为三个部分:左侧为数据输入(采集),中间为数据处理(计算),右侧为数据分析(展现和输出)。
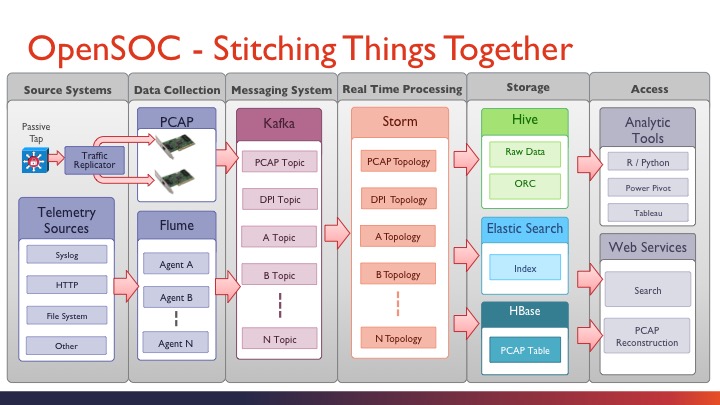
再来看看其数据流框架,在概念性框架的基础上,把每一步的功能组件都一一列清楚了。分为六个部分:
- Source Systems,数据输入源,分为主动和被动两种方式;
- Data Collection,数据收集,主要采用Flume进行数据收集和预处理,PCAP进行抓包收集;
- Messaging System,消息系统,主要是Kafka分布式消息系统进行数据缓存,根据数据源不一样来划分不同的topic;
- Real Time Processing,实时处理,主要采用Storm实时计算框架进行数据整理,聚合,DPI分析,等,这里,每个kafka topic都需要单独的storm 应用程序来独立处理;
- Storage,存储,就是把计算的结果和原始数据写入相应的存储模块,原始数据存入Hive,日志数据存入ElasticSearch便于索引查找(结合kibana),抓包数据存入HBase;
- Access,访问层,简单说就是把分析结果数据从存储中取出来,通过各种BI工具渲染到页面,当然,也可以把数据以web service的方式提供给第三方。
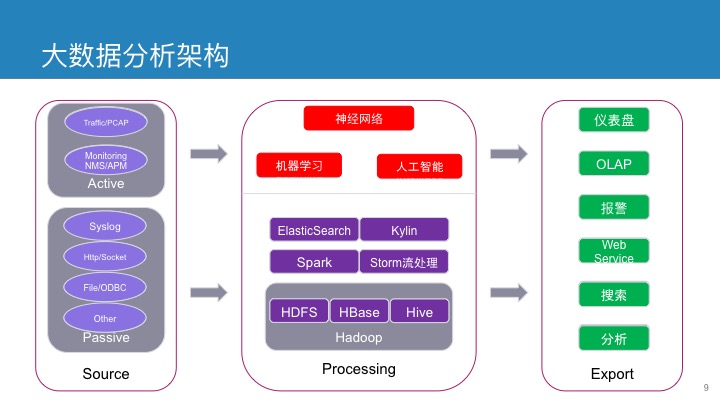
赛克通公司在大数据处理方面,也有自己的一套计算框架,此框架可调整性相对较大,可以根据用户数据体量,计算要求灵活变换。
核心计算模型
OpenSOC核心计算模型采用Storm来负责处理,前面提到过,每个设备或数据流,都需要单独的storm应用程序(topology,拓扑)来进行运算,这个对于部署storm应用的时候特别要注意了。 当然,storm是分布式计算框架,应用程序多的话只需要增加物理计算机就能解决,不是什么大问题。
PCAP分析拓扑
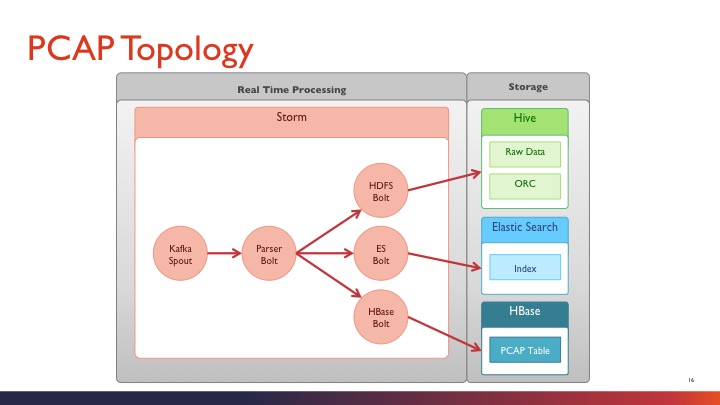
由图示可以看出,storm的kafka spout获取到的pcap数据,经过基本解析后即存入相应的存储模块,并没有太多的计算内容。这个相对而言比较容易理解。
DPI分析拓扑
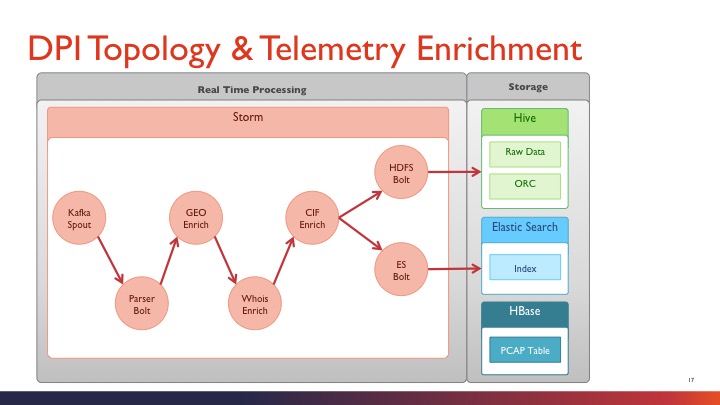
由图示看出,DPI拓扑中,计算引擎做的功能比pcap多了许多,中间关联了很多其他模块,比如:whois查询,GEO地址定位等,丰富了分析的内容。 由此可以联想到,在DPI拓扑中,我们可以增加其他的第三方关联,比如:botnet僵尸网络知识库,ip reputation数据库(ossim提供),舆情数据库等,这样这个计算框架就强大了许多,可以做的分析也就更多。
Enrichment高级分析
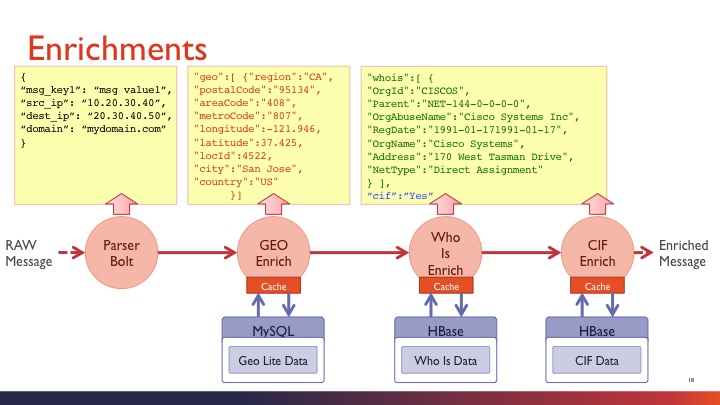
高级分析模块详解,这里把每个步骤的数据流都做了对照,GEO信息来自MySQL数据库,whois信息和CIF来自HBase数据库。
更多的关于最佳实践和学习,请参照官方发布的PPT内容。
OpenSOC 改进建议
总体框架性改进
总体框架上,可以让OpenSOC更加灵活一些,处理流程可以更加简化一些。比如:由storm计算完成之后,不一定由storm直接写入相应存储(mysql,hive,hbase,es等), 而是再次丢入kafka(其他应用和计算框架还能重复利用),由另外的程序来进行执行写入操作,这样减轻了storm的负担,增加了灵活性。
处理引擎类改进
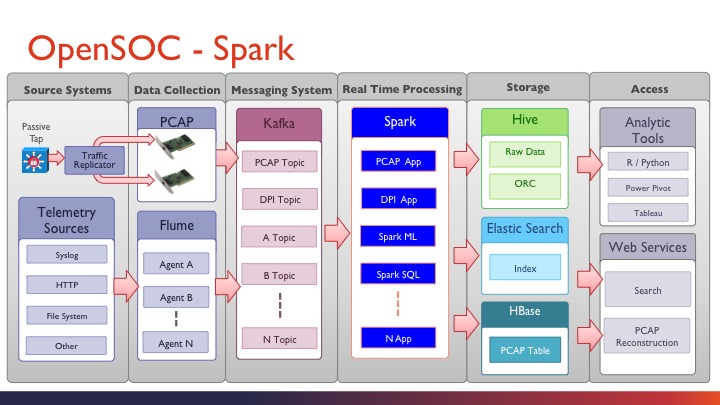
大数据工程师都知道,storm是实时处理引擎,时效性非常好。但是,需要加入机器学习或SQL引擎时,storm就失色了。这时候,Spark来了,有可能替代hadoop的引擎出现了,对于应用开发更加轻松。不多说,上图。

可视化引擎改进
我们都知道,OpenSOC可视化引擎用的kibana,kibana能做的事情很多很多,当然,kibana对于elasticsearch非常合适,其他的就不一定了。所以,必须要结合相应的BI工具,比如:Tableau,Power Pivot等。 如果由spark代替了storm作为计算引擎,可以在可视化框架中加入zeppelin(一个基于spark的开源可视化notebook工具),直接在zeppelin中将业务逻辑梳理好,这样更加快速的加速spark的开发。 关于zeppelin的详细信息请参见【数据可视化】Zeppelin JDBC 数据可视化(WEB方式)
原文地址:https://blog.sectong.com/blog/opensoc_deep_analysis.html
标签: OpenSOC, SOC, syslog, 态势感知, 日志审计, 日志管理