机器学习的核心是“使用算法解析数据,从中学习,然后对世界上的某件事情做出决定或预测”。
机器学习的目标是使学到的函数很好地适用于“新样本”,而不仅仅是在训练样本上表现很好。
所谓的训练数据,就是经过预处理(一般是人工标注)后,有相对稳妥、精确的特征描述的数据集,以“样本”形式参与模型开发工作。
训练数据选择一般有以下要求:数据样本尽可能大、数据多样化,数据样本质量较高。
需要把握这样几个原则。
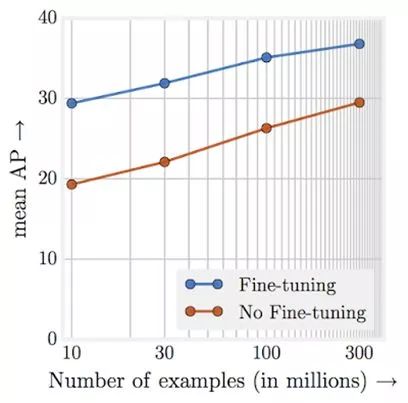
Facebook最近更加深入的使用大数据量,例如,在ImageNet分类中使用了数十亿个带有标签的Instagram图片,以达到新的记录精度。
这表明,即使对于大型、高质量数据集的问题,增加训练集的大小仍然可以提高模型结果。
混乱的数据是数据科学家工作流中典型的比较耗费时间的。
对这一点我们应该有足够的心理准备,并且在实际工作中,为训练数据的收集留出较充足的时间。
前面说过,训练数据的正确性对模型质量有非常非常大的影响。
在机器学习领域有个重要原则,GIGO原则(Garbage In Garbage Out),即垃圾进,垃圾出。
就是说如果训练数据就是不准确的无价值的,那么无论你的算法多么优秀都难以获得一个好的机器学习成果。
对于一些简单的常识性的标注工作比如标注商品,判断数字大小、标注方位,基本没有门槛,可以通过简单增加人手解决。
但对专业知识要求很高或数据内容较为复杂的任务,比如对癌细胞X光片的标注,对物种分类的标注这还真就必须得由有一定专业知识的人来做。
对标注的管理往往是对人以及信息的管理。依靠人力的标注很难百分百保证正确性。
为了保证大的正确率。需要通过各种工程手段、管理方法,从立项、准备数据到确定标注群体、确定工期、确定标注规则、标注、质量审核、数据过滤、算法验收等等,确保每个步骤尽量不要出现纰漏。
当然,在保质保量、按时完成的前提下,我们还需要考虑成本。很多人把数据比喻成人工智能的煤炭能源,但目前此行业较混乱,较原始,问题多,行业新,人才少。
杭州世平信息科技有限公司(简称“世平信息”),致力于智能化数据管理与应用的深入开拓和持续创新,为用户提供数据安全、数据治理、数据共享和数据利用解决方案,帮助用户切实把握大数据价值与信息安全。