



摘要:作为一个有点辈分的DBA,我的日常是“救火”于危难之中24小时待命,客户“十万火急”电话分分钟彪过来 定期还要人工现场巡检 自从有了运维云, 我立下“不再做一个普通的DBA”的志愿 我的工作日常变了样儿~比如,某一天早上。手机上收到一条来自运...
定期还要人工现场巡检
自从有了运维云,
我立下“不再做一个普通的DBA”的志愿
我的工作日常变了样儿~
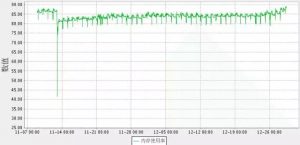
(图1:1节点的内存使用状况)
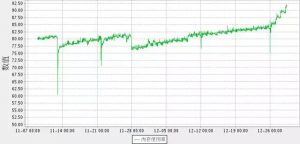
(图2:2节点的内存使用状况)
从上面的图形上能够明显的看到,从26日之后,2个节点的内存使用率节节上升。按这个趋势,2节点的内存,用不了几天就会爆掉了。
于是乎,凭借我的超敏感嗅觉,开始逐一原因排查。
原因排查
从数据库的dba_hist_process_mem_summary中查看内存的使用,取问题发生的前一天(25日,snap_id为51946)到今天为止,每天早上8点到9点这个时间段内的内存使用情况:
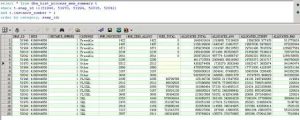
(图3:1节点的数据库内存使用分布)
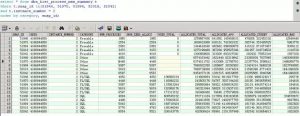
(图4:2节点的数据库内存使用分布)
从图3和4中也可以看到,2个节点上,自26日之后,每个类型的内存使用,都在随着process的不断增加而上涨。
对于这个内存问题,第一反应是25日晚上的一次应用系统升级引起的。如果是应用服务的增加,应该是上涨之后稳定下来,而不是持续上升,因此,最可能的原因是某个新上的程序有bug,在持续地新建会话,而不释放老会话。
再次打开运维云监控,查看2个节点上的会话信息:
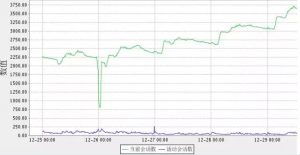
(图5:1节点会话数趋势图)
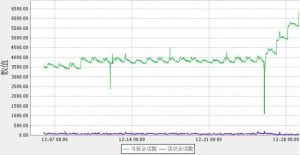
(图6:2节点会话数趋势图)
从图5,6中可以看到,2个节点上的会话数都在不断的上涨中,尤其是2节点,从3500左右涨到6000左右,按趋势来看,没有停止的趋势。这也证实了前面的推论,只需找出哪个程序出问题即可。
会话上涨了2500左右,应该能在gv$session里面能查到比较直接的结果。可以使用以下语句查看:
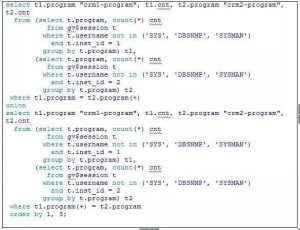
从查询结果中,确实能够找到一个连接数异常高的进程,2个节点上都有连接,2节点尤其高。
![]()
再从连接过来的客户端服务器上,查这个serv_SyncVpnMe的程序。
![]()
果然,这个程序的启动时间正好是26日凌晨,也就是系统升级那天。到这里,算是揪出了“罪魁祸首”。
发现问题,如何解决,也是DBA的职责所在。
故障解决
找到相关开发人员说明排查结果,协商后停掉该问题程序,数据库的session很快就降了下来,2个节点的内存都立即降到了正常水平。
再次从监控系统中查看会话情况,结果如下:
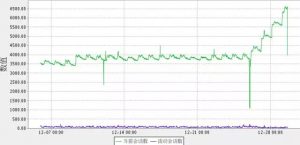
(图7:2节点异常程序停掉后的会话趋势图)
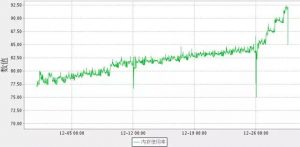
(图8:2节点异常程序停掉后的内存趋势图)
作为一个勤于思考的DBA,我做了进一步推敲:
以往:运维人员手握大量数据库,面对层出不穷的数据库问题,时间和精力难免会分散,不可能时时兼顾每一套数据库,察觉每一个潜在隐患。在没有监控的情况下,按照以往的运维模式,可能得等到数据库连接占满,或者是系统资源耗尽之时,数据库无法提供服务了,运维人员直到接到客户的投诉电话才会意识到出故障了。而往往在这个时候,即便迅速、顺利地处理了故障,仍然已经影响到用户体验,属于严重滞后了。
现在:而实时的监控所有在运系统的运行状况,及时发现问题隐患并产生告警,通过邮件、短信等方式第一时间通知到一线运维人员,运维人员收到信息后及时处理,可以有效避免问题进一步扩大化,是新时期运维的必要手段。
不会打广告的DBA不是好写手,冷不丁的打了一个小广告。哈哈。

