



摘要: 前一段时间,有个华为在职的朋友来找我咨询一些大数据分析技术,关于架构方面的比较,特地做了个PPT,现在放出来大家一起探讨一下。 PPT大概意思就是说要准备做一个大数据平台,至于做具体的内容也没有明确说法,那针对这种情况,只能是把大数据分析一些比较粗略说明一下。...
前一段时间,有个华为在职的朋友来找我咨询一些大数据分析技术,关于架构方面的比较,特地做了个PPT,现在放出来大家一起探讨一下。
PPT大概意思就是说要准备做一个大数据平台,至于做具体的内容也没有明确说法,那针对这种情况,只能是把大数据分析一些比较粗略说明一下。也算是普及一下。
首先说明,很多人用ELK作为大数据分析的入口,不为过,很好。
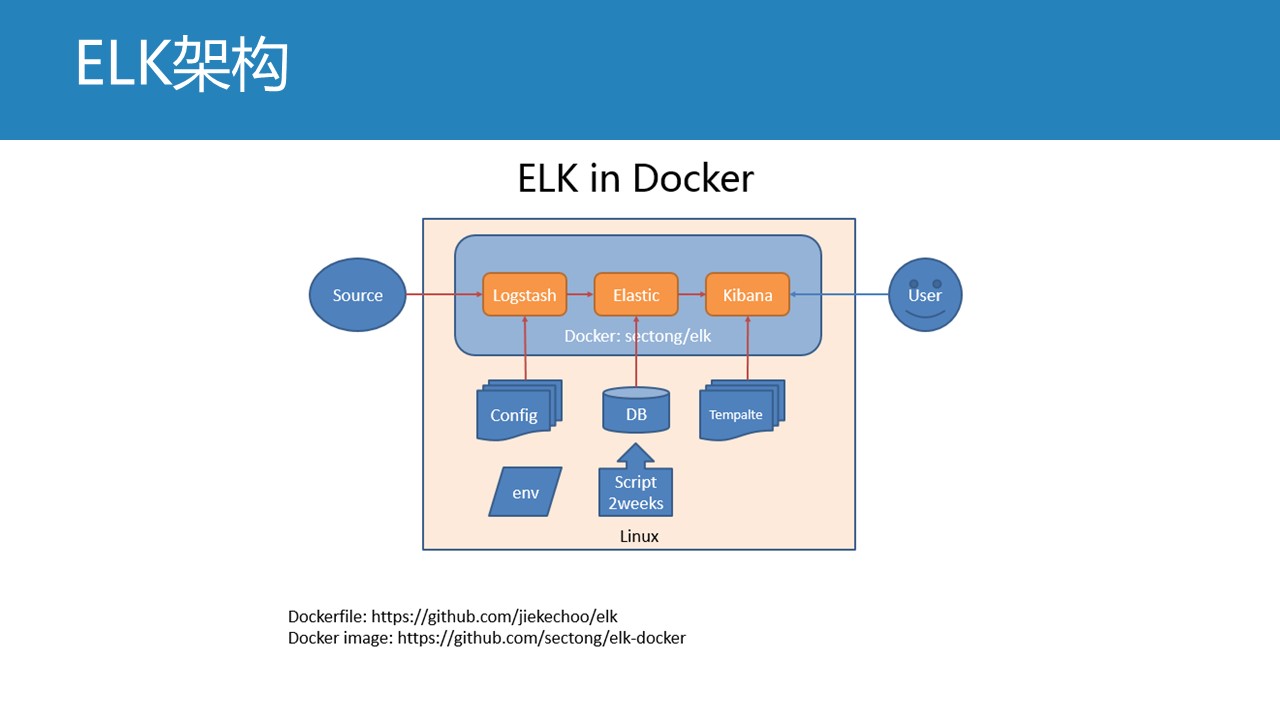
咱有二次开发的开源框架,供你使用。全部开源
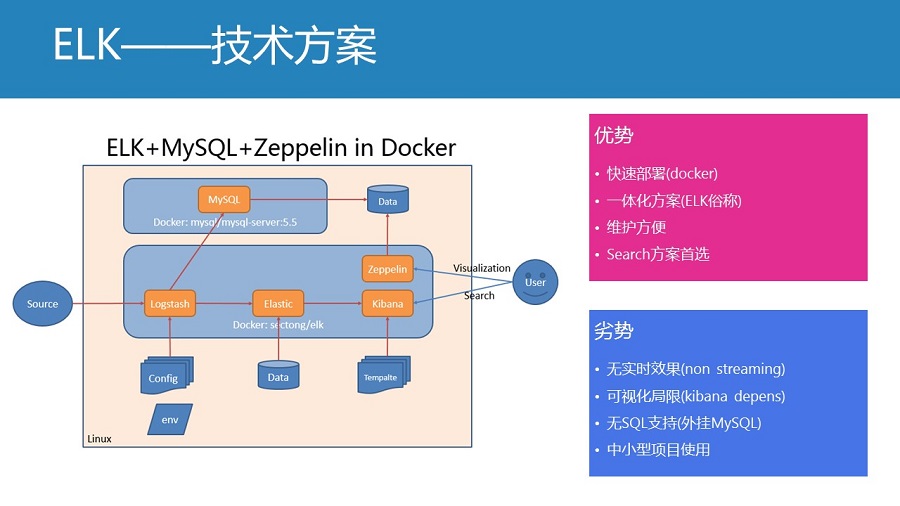
用到Hadoop生态链,那高大山多了
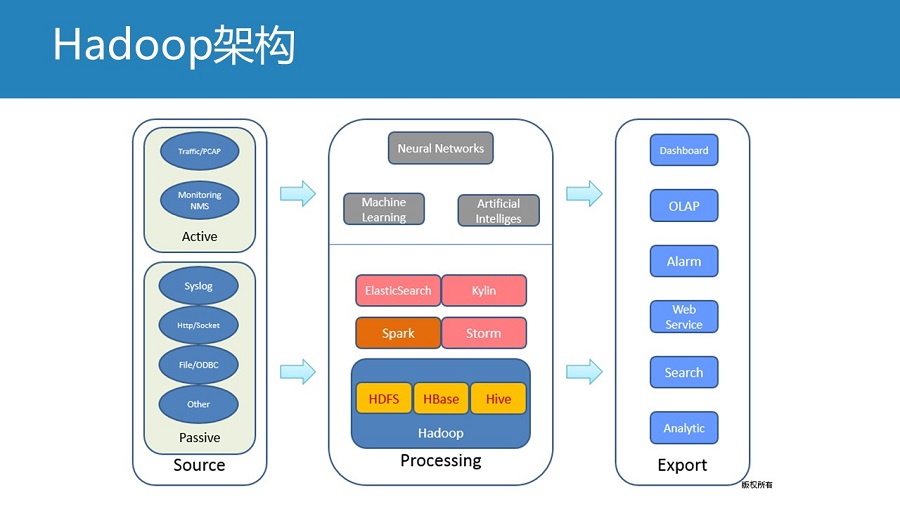
再高大山的内容,也有优劣势,比较一下

很多人说Spark会代替Hadoop生态链里面很多内容,我举双手同意
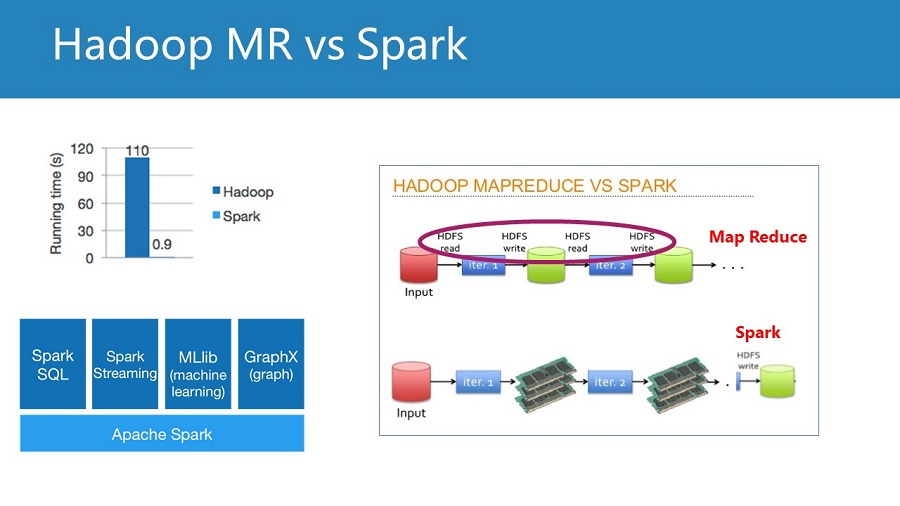
你说流处理?那我们来聊聊streaming技术,还是推荐Spark

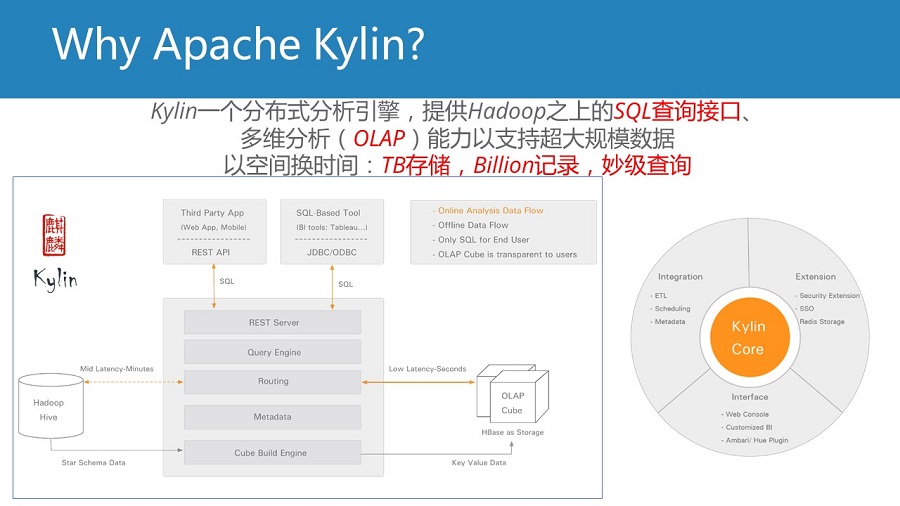
Apache Kylin 听说过吗?那才是真正的高大山,华人开发的,一个字:牛逼!
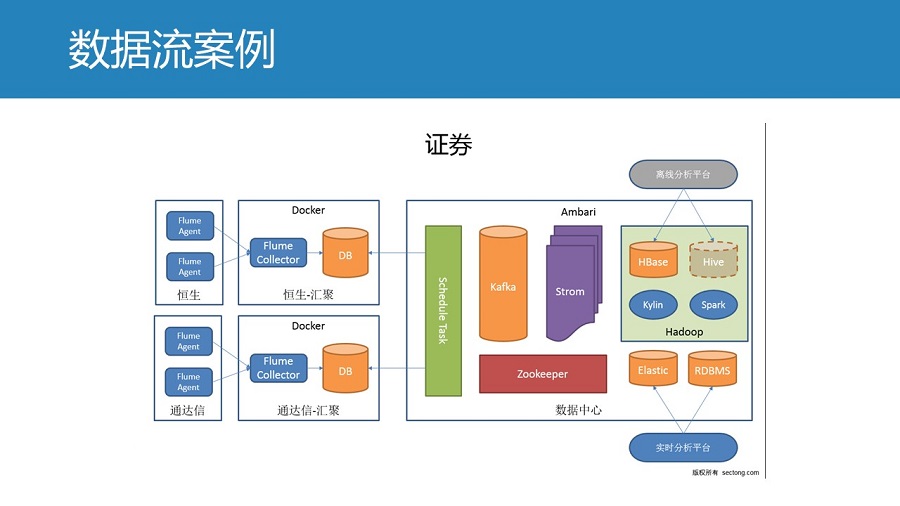
证券行业,现在“大力发展”大数据,是个机会,但是一般企业进去不这个行业,游戏规则啦,你懂的。
这个案例分析说明了,用Kylin,大数据实时关联分析已经不是问题。不信你问问luke han。
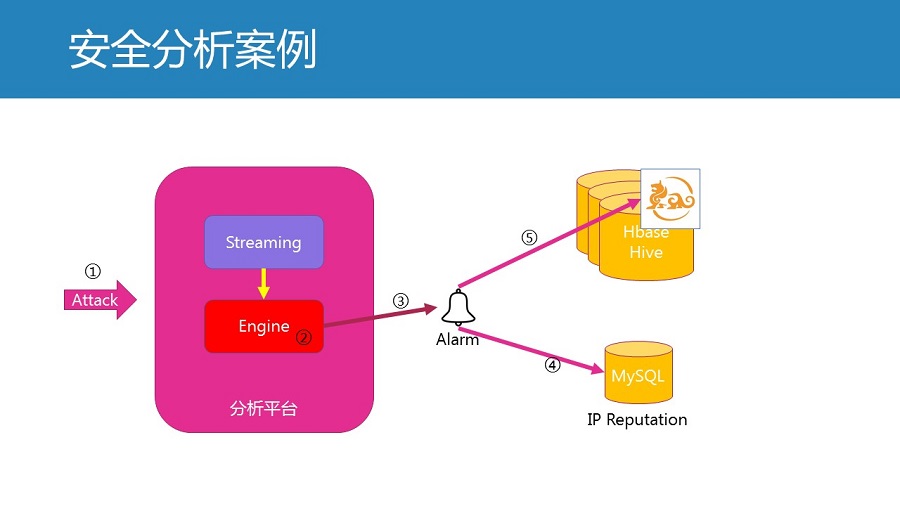
你想了解更多详情,可以找赛克通的顾问,电话你到sectong.com查一下啊。
原文地址:http://blog.sectong.com/blog/hw_bigdata.html

