本文最初思路来自 http://www.sparkexpert.com ,但是,发现 https://github.com/sujee81/SparkApps 提供的源码太老了,Spark官方从1.4.0已经放弃原来的方法(包含:createJDBCTable,insertIntoJDBC等 ),取而代之的是 sqlContext.read().jdbc()和sqlContext.write().jdbc()方法。
一、源码下载
git clone https://github.com/jiekechoo/spark-jdbc-apps.git源代码目录如下,今天主要说明前面两个:
spark-load-from-db:从数据库读取
spark-save-to-db:保存到数据库
spark-stats:下一篇文章介绍
spark-jdbcrdd:下一篇文章介绍二、源码分析
依赖包分析
父项目pom,定义了共用组件slf4j,spark版本1.5.1,mysql5.1.32等
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.sectong</groupId>
<artifactId>spark-apps-parent</artifactId>
<version>1.0-SNAPSHOT</version>
<name>spark-apps-parent</name>
<packaging>pom</packaging>
<modules>
<module>spark-jdbcrdd</module>
<module>spark-load-from-db</module>
<module>spark-save-to-db</module>
<module>spark-stats</module>
</modules>
<dependencies>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
<version>1.7.13</version>
</dependency>
</dependencies>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<spark.version>1.5.1</spark.version>
<mysql.version>5.1.32</mysql.version>
</properties>
</project>保存到数据库spark-save-to-db
依赖包,主要是spark-core和spark-sql,还有mysql驱动:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>com.sectong</groupId>
<artifactId>spark-apps-parent</artifactId>
<version>1.0-SNAPSHOT</version>
</parent>
<artifactId>spark-save-to-db</artifactId>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.10</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.10</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>${mysql.version}</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.2</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
<compilerArgument>-Xlint:all</compilerArgument>
<showWarnings>true</showWarnings>
<showDeprecation>true</showDeprecation>
</configuration>
</plugin>
</plugins>
</build>
</project>看源码:
package com.sectong;
import java.io.Serializable;
import java.util.Properties;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.sql.DataFrame;
import org.apache.spark.sql.SQLContext;
import org.apache.spark.sql.SaveMode;
public class Main implements Serializable {
/**
*
*/
private static final long serialVersionUID = -8513279306224995844L;
private static final String MYSQL_USERNAME = "demo";
private static final String MYSQL_PWD = "demo";
private static final String MYSQL_CONNECTION_URL = "jdbc:mysql://192.168.1.91:3306/demo";
private static final JavaSparkContext sc = new JavaSparkContext(new SparkConf().setAppName("SparkSaveToDb").setMaster("local[*]"));
private static final SQLContext sqlContext = new SQLContext(sc);
public static void main(String[] args) {
// Sample data-frame loaded from a JSON file
DataFrame usersDf = sqlContext.read().json("users.json");
// Save data-frame to MySQL (or any other JDBC supported databases)
Properties connectionProperties = new Properties();
connectionProperties.put("user", MYSQL_USERNAME);
connectionProperties.put("password", MYSQL_PWD);
// write dataframe to jdbc mysql
usersDf.write().mode(SaveMode.Append).jdbc(MYSQL_CONNECTION_URL, "users", connectionProperties);
}
}我们为了写入数据方便测试,需要一个json文件,类似下方:
{"id":994,"name":"Betty","email":"bsmithrl@simplemachines.org","city":"Eláteia","country":"Greece","ip":"9.19.204.44"},
{"id":995,"name":"Anna","email":"alewisrm@canalblog.com","city":"Shangjing","country":"China","ip":"14.207.119.126"},
{"id":996,"name":"David","email":"dgarrettrn@japanpost.jp","city":"Tsarychanka","country":"Ukraine","ip":"111.252.63.159"},
{"id":997,"name":"Heather","email":"hgilbertro@skype.com","city":"Koilás","country":"Greece","ip":"29.57.181.250"},
{"id":998,"name":"Diane","email":"ddanielsrp@statcounter.com","city":"Mapiripán","country":"Colombia","ip":"19.205.181.99"},
{"id":999,"name":"Philip","email":"pfullerrq@reuters.com","city":"El Cairo","country":"Colombia","ip":"210.248.121.194"},
{"id":1000,"name":"Maria","email":"mfordrr@shop-pro.jp","city":"Karabash","country":"Russia","ip":"224.21.41.52"}读取文件时,users.json需要与jar包在同一目录下,测试采用本地运行方式:
DataFrame usersDf = sqlContext.read().json("users.json");其中,代码中的这行mode(SaveMode.Append)要特别注意,这个使得每次写入的数据是增加到数据表中。否则会一直提 示:Exception in thread “main” java.lang.RuntimeException: Table users already exists.
usersDf.write().mode(SaveMode.Append).jdbc(MYSQL_CONNECTION_URL, "users", connectionProperties);打包,上传spark运行:
/opt/spark/bin/spark-submit --class com.sectong.Main --driver-class-path mysql-connector-java-5.1.32.jar spark-save-to-db-1.0-SNAPSHOT.jar 结果就是下面这样了: 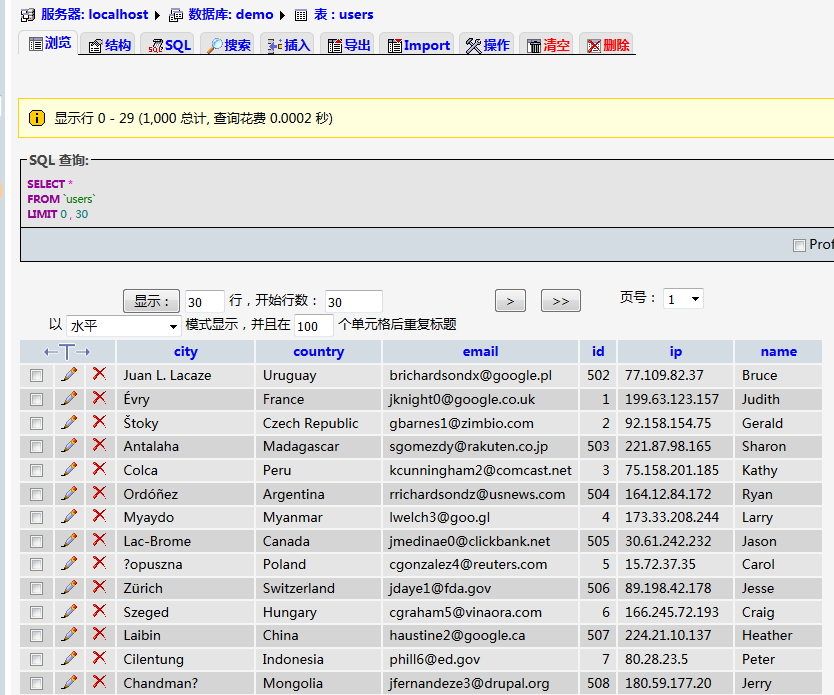
从数据库读取spark-load-from-db
依赖包与保存数据基本一致,不再说明。
看源码:
package com.sectong;
import java.io.Serializable;
import java.util.List;
import java.util.Properties;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.sql.DataFrame;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.SQLContext;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
public class Main implements Serializable {
/**
*
*/
private static final long serialVersionUID = -8513279306224995844L;
private static final Logger LOGGER = LoggerFactory.getLogger(Main.class);
private static final String MYSQL_USERNAME = "demo";
private static final String MYSQL_PWD = "demo";
private static final String MYSQL_CONNECTION_URL = "jdbc:mysql://192.168.1.91:3306/demo";
private static final JavaSparkContext sc = new JavaSparkContext(new SparkConf().setAppName("SparkJdbcFromDb").setMaster("local[*]"));
private static final SQLContext sqlContext = new SQLContext(sc);
public static void main(String[] args) {
Properties properties = new Properties();
properties.put("user", MYSQL_USERNAME);
properties.put("password", MYSQL_PWD);
// Load MySQL query result as DataFrame
DataFrame jdbcDF = sqlContext.read().jdbc(MYSQL_CONNECTION_URL, "users", properties);
List<Row> employeeFullNameRows = jdbcDF.collectAsList();
for (Row employeeFullNameRow : employeeFullNameRows) {
LOGGER.info(employeeFullNameRow.toString());
}
}
}读取MySQL数据,这行最关键:
DataFrame jdbcDF = sqlContext.read().jdbc(MYSQL_CONNECTION_URL, "users", properties);再打印出来:
List<Row> employeeFullNameRows = jdbcDF.collectAsList();
for (Row employeeFullNameRow : employeeFullNameRows) {
LOGGER.info(employeeFullNameRow.toString());
}Spark运行程序,注意–driver-class-path mysql-connector-java-5.1.32.jar参数,需要把mysql-connector挂载上:
/opt/spark/bin/spark-submit --class com.sectong.Main --driver-class-path mysql-connector-java-5.1.32.jar spark-load-from-db-1.0-SNAPSHOT.jar 中间运行省略了,把结果输出:
2016-01-06 08:14:01[main] INFO Main:43 - [Matriz de Camaragibe,Brazil,sgarciadp@nifty.com,494,39.244.171.48,Steven]
2016-01-06 08:14:01[main] INFO Main:43 - [Huarancante,Peru,njacksondq@si.edu,495,67.123.78.80,Nicholas]
2016-01-06 08:14:01[main] INFO Main:43 - [Zandak,Russia,sjonesdr@nbcnews.com,496,167.69.237.11,Sarah]
2016-01-06 08:14:01[main] INFO Main:43 - [Somovo,Russia,jgardnerds@nsw.gov.au,497,112.190.104.80,Judy]
2016-01-06 08:14:01[main] INFO Main:43 - [Huaping,China,calexanderdt@blinklist.com,498,79.242.142.206,Christine]
2016-01-06 08:14:01[main] INFO Main:43 - [Isulan,Philippines,wgomezdu@imdb.com,499,26.220.121.74,Wanda]
2016-01-06 08:14:01[main] INFO Main:43 - [Wujiayao,China,wleedv@latimes.com,500,26.104.219.178,Walter]
2016-01-06 08:14:01[main] INFO Main:43 - [Dongtou,China,hriveradw@skype.com,501,82.13.121.35,Henry]
2016-01-06 08:14:01[Thread-3] INFO SparkContext:59 - Invoking stop() from shutdown hook
2016-01-06 08:14:01[Thread-3] INFO ContextHandler:843 - stopped o.s.j.s.ServletContextHandler{/static/sql,null}
2016-01-06 08:14:01[Thread-3] INFO ContextHandler:843 - stopped o.s.j.s.ServletContextHandler{/SQL/execution/json,null}微信公众服务号:sectong
原文地址: http://blog.sectong.com/blog/spark_jdbc_load_save.html